
Before learning the intricacies of HTML (Hypertext Markup Language) and CSS (Cascading Style Sheets), it is important to gain a solid understanding of the technologies that help transform these plain-text files to the rich multimedia displays you see on your computer or handheld device when browsing the World Wide Web.
For example, a file containing markup and client-side code HTML and CSS is useless without a web browser to view it, and no one besides yourself will see your content unless a web server is involved. Web servers make your content available to others who, in turn, use their web browsers to navigate to an address and wait for the server to send information to them. You will be intimately involved in this publishing process because you must create files and then put them on a server to make them available in the first place, and you must ensure that your content will appear to the end user as you intended.
Once upon a time, back when there weren’t any footprints on the moon, some farsighted folks decided to see whether they could connect several major computer networks. I’ll spare you the names and stories (there are plenty of both), but the eventual result was the “mother of all networks,” which we call the Internet.
Until 1990, accessing information through the Internet was a rather technical affair. It was so hard, in fact, that even Ph.D.-holding physicists were often frustrated when trying to swap data. One such physicist, the now-famous (and knighted) Sir Tim Berners-Lee, cooked up a way to easily cross-reference text on the Internet through hypertext links.
This wasn’t a new idea, but his simple Hypertext Markup Language (HTML) managed to thrive while more ambitious hypertext projects floundered. Hypertext originally meant text stored in electronic form with cross-reference links between pages. It is now a broader term that refers to just about any object (text, images, files, and so on) that can be linked to other objects. Hypertext Markup Language is a language for describing how text, graphics, and files containing other information are organized and linked.
By 1993, only 100 or so computers throughout the world were equipped to serve up HTML pages. Those interlinked pages were dubbed the World Wide Web (WWW), and several web browser programs had been written to allow people to view web pages. Because of the growing popularity of the web, a few programmers soon wrote web browsers that could view graphical images along with text. From that point forward, the continued development of web browser software and the standardization of the HTML—and XHTML—languages has led us to the world we live in today, one in which more than half a billion websites serve billions of text and multimedia files.
These few paragraphs really are a brief history of what has been a remarkable period. Today’s college students have never known a time in which the World Wide Web didn’t exist, and the idea of always-on information and ubiquitous computing will shape all aspects of our lives moving forward. Instead of seeing web content creation and management as a set of skills possessed only by a few technically oriented folks (okay, call them geeks, if you will), by the end of this book, you will see that these are skills that anyone can master, regardless of inherent geekiness.
Note
For more information on the history of the World Wide Web, see the Wikipedia article on this topic: http://en.wikipedia.org/wiki/History_of_the_Web.
You might have noticed the use of the term web content rather than web pages—that was intentional. Although we talk of “visiting a web page,” what we really mean is something like “looking at all the text and the images at one address on our computer.” The text that we read, and the images that we see, are rendered by our web browsers, which are given certain instructions found in individual files.
Those files contain text that is marked up, or surrounded by, HTML codes that tell the browser how to display the text—as a heading, as a paragraph, in a red font, and so on. Some HTML markup tells the browser to display an image or video file rather than plain text, which brings me back to the point: Different types of content are sent to your web browser, so simply saying web page doesn’t begin to cover it. Here we use the term web content instead, to cover the full range of text, image, audio, video, and other media found online.
In later hours, you learn the basics of linking to or creating the various types of multimedia web content found in websites. All you need to remember at this point is that you are in control of the content a user sees when visiting your website. Beginning with the file that contains text to display or codes that tell the server to send a graphic along to the user’s web browser, you have to plan, design, and implement all the pieces that will eventually make up your web presence. As you will learn throughout this book, it is not a difficult process as long as you understand all the little steps along the way.
In its most fundamental form, web content begins with a simple text file containing HTML markup. In this book, you learn about and compose standards-compliant HTML5 markup. One of the many benefits of writing standards-compliant code is that, in the future, you will not have to worry about having to go back to your code to fundamentally alter it. Instead, your code will (likely) always work for as long as web browsers adhere to standards (hopefully a long time).
Several processes occur, in many different locations, to eventually produce web content that you can see. These processes occur very quickly—on the order of milliseconds—and occur behind the scenes. In other words, although we might think all we are doing is opening a web browser, typing in a web address, and instantaneously seeing the content we requested, technology in the background is working hard on our behalf. Figure 1.1 shows the basic interaction between a browser and a server.
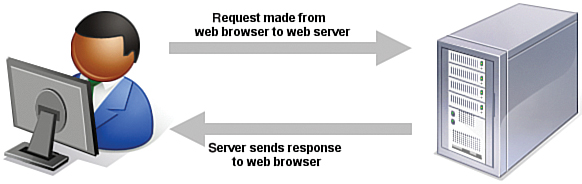
FIGURE 1.1 A browser request and a server response.
However, the process involves several steps—and potentially several trips between the browser and the server—before you see the entire content of the site you requested.
Suppose you want to do a Google search, so you dutifully type http://www.google.com in the address bar or select the Google bookmark from your bookmarks list. Almost immediately, your browser shows you something like Figure 1.2.
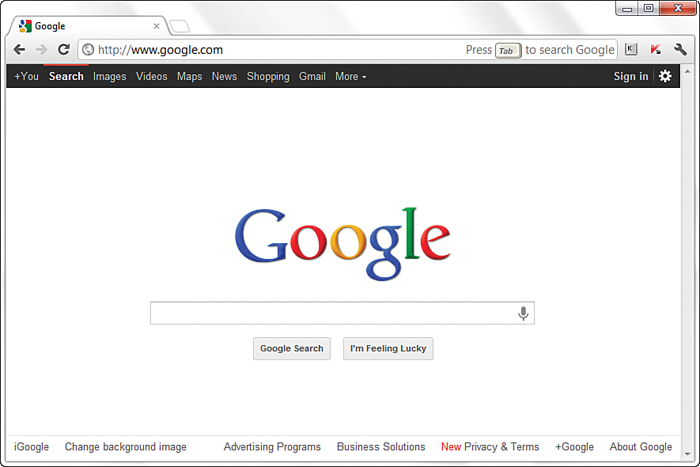
FIGURE 1.2 Visiting www.google.com.
Figure 1.2 shows a website that contains text plus one image (the Google logo). A simple version of the processes that occurred to retrieve that text and image from a web server and display it on your screen follows:
index.html file located at the www.google.com address. The index.html file does not have to be part of the address that you type in the address bar; you learn more about the index.html file further along in this hour.index.html file, which is text marked up with HTML codes, and renders the content based on these HTML codes. While rendering the content, the browser happens upon the HTML code for the Google logo, which you can see in Figure 1.2. The HTML code looks something like this:
<img alt="Google" src="/images/srpr/logo4w.png" width="275" height="95" />
The tag provides attributes that tell the browser the file source location (src), width (width), height (height), border type (border), and alternative text (alt) necessary to display the logo. You learn more about attributes throughout later lessons.
src attribute in the <img/> tag to find the source location. In this case, the image logo3w.png can be found in the images directory at the same web address (www.google.com) from which the browser retrieved the HTML file.As you can see in the description of the web content delivery process, web browsers do more than simply act as picture frames through which you can view content. Browsers assemble the web content components and arrange those parts according to the HTML commands in the file.
You can also view web content locally, or on your own hard drive, without the need for a web server. The process of content retrieval and display is the same as the process listed in the previous steps, in that a browser looks for and interprets the codes and content of an HTML file, but the trip is shorter: The browser looks for files on your own computer’s hard drive rather than on a remote machine. A web server would be needed to interpret any server-based programming language embedded in the files, but that is outside the scope of this book. In fact, you could work through all the lessons in this book without having a web server to call your own, but then nobody but you could view your masterpieces.
Despite just telling you that you can work through all the lessons in this book without having a web server, having a web server is the recommended method for continuing on. Don’t worry—obtaining a hosting provider is usually a quick, painless, and relatively inexpensive process. In fact, you can get your own domain name and a year of web hosting for just slightly more than the cost of the book you are reading now.
If you type web hosting provider in your search engine of choice, you will get millions of hits and an endless list of sponsored search results (also known as ads). Not this many web hosting providers exist in the world, although it might seem otherwise. Even if you are looking at a managed list of hosting providers, it can be overwhelming—especially if all you are looking for is a place to host a simple website for yourself or your company or organization.
You’ll want to narrow your search when looking for a provider and choose one that best meets your needs. Some selection criteria for a web hosting provider follow:
Here are three reliable web hosting providers whose basic packages contain plenty of server space and bandwidth (as well as domain names and extra benefits) at a relatively low cost. If you don’t go with any of these web hosting providers, you can at least use their basic package descriptions as a guideline as you shop around.
Note
The author has used all these providers (and then some) over the years and has no problem recommending any of them; predominantly, she uses DailyRazor as a web hosting provider, especially for advanced development environments.
One feature of a good hosting provider is that it provides a “control panel” for you to manage aspects of your account. Figure 1.3 shows the control panel for my own hosting account at Daily Razor. Many web hosting providers offer this particular control panel software, or some control panel that is similar in design—clearly labeled icons leading to tasks you can perform to configure and manage your account.
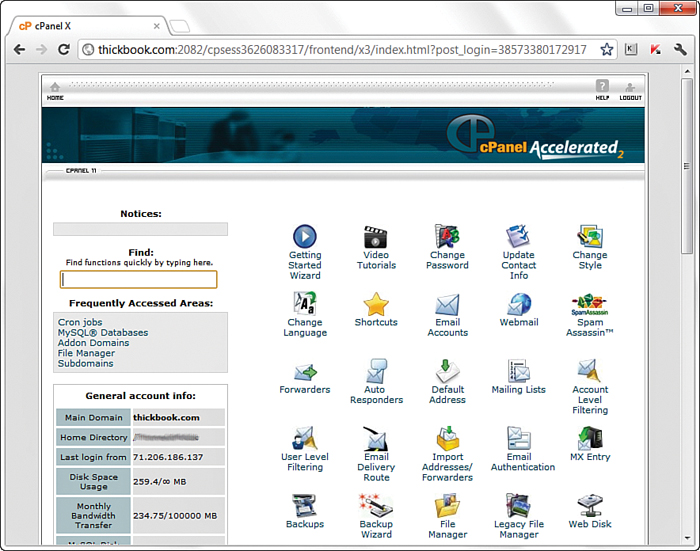
FIGURE 1.3 A sample control panel.
You might never need to use your control panel, but having it available to you simplifies the installation of databases and other software, the viewing of web statistics, and the addition of email addresses (among many other features). If you can follow instructions, you can manage your own web server—no special training required.
Having just discussed the process of web content delivery and the acquisition of a web server, it might seem a little strange to step back and talk about testing your websites with multiple web browsers. However, before you go off and learn all about creating websites with HTML and CSS, do so with this very important statement in mind: Every visitor to your website will potentially use hardware and software configurations that are different than your own. Their device types (desktop, laptop, netbook, smartphone, iPhone), screen resolutions, browser types, browser window sizes, speed of connections—remember that you cannot control any aspect of what your visitors use when they view your site. So just as you’re setting up your web hosting environment and getting ready to work, think about downloading several different web browsers so that you have a local test suite of tools available to you. Let me explain why this is important.
Although all web browsers process and handle information in the same general way, some specific differences among them result in things not always looking the same in different browsers. Even users of the same version of the same web browser can alter how a page appears by choosing different display options and/or changing the size of their viewing windows. All the major web browsers allow users to override the background and fonts the web page author specifies with those of their own choosing. Screen resolution, window size, and optional toolbars can also change how much of a page someone sees when it first appears on their screens. You can ensure only that you write standards-compliant HTML and CSS.
Do not, under any circumstances, spend hours on end designing something that looks perfect only on your own computer—unless you are willing to be disappointed when you look at it on your friend’s computer, the computer in the coffee shop down the street, on your iPhone.
Note
In Hour 15, you’ll learn a little bit about the concept of responsive web design, in which the design of a site shifts and changes automatically depending on the user’s behavior and viewing environment (screen size, device, and so on).
You should always test your websites with as many of these web browsers as possible:
Now that you have a development environment set up, or at least some idea of the type you’d like to set up in the future, let’s move on to creating a test file.
Before we begin, take a look at Listing 1.1. This listing represents a simple piece of web content—a few lines of HTML that print "Hello World! Welcome to My Web Server." in large, bold letters on two lines centered within the browser window. You’ll learn more about the HTML and CSS used within this file as you move forward in this book.
LISTING 1.1 Our Sample HTML File
To make use of this content, open a text editor of your choice, such as Notepad (on Windows) or TextEdit (on a Mac). Do not use WordPad, Microsoft Word, or other full-featured word-processing software because those programs create different sorts of files than the plain-text files we use for web content.
Type the content that you see in Listing 1.1 and then save the file using sample.html as the filename. The .html extension tells the web server that your file is, indeed, full of HTML. When the file contents are sent to the web browser that requests it, the browser will also know that it is HTML and will render it appropriately.
Now that you have a sample HTML file to use—and hopefully somewhere to put it, such as a web hosting account—let’s get to publishing your web content.
As you’ve learned so far, you have to put your web content on a web server to make it accessible to others. This process typically occurs by using File Transfer Protocol (FTP). To use FTP, you need an FTP client—a program used to transfer files from your computer to a web server.
FTP clients require three pieces of information to connect to your web server; this information will have been sent to you by your hosting provider after you set up your account:
When you have this information, you are ready to use an FTP client to transfer content to your web server.
Regardless of the FTP client you use, FTP clients generally use the same type of interface. Figure 1.4 shows an example of FireFTP, which is an FTP client used with the Firefox web browser. The directory listing of the local machine (your computer) appears on the left of your screen, and the directory listing of the remote machine (the web server) appears on the right. Typically, you will see right arrow and left arrow buttons, as shown in Figure 1.4. The right arrow sends selected files from your computer to your web server; the left arrow sends files from the web server to your computer. Many FTP clients also enable you to simply select files and then drag and drop those files to the target machines.
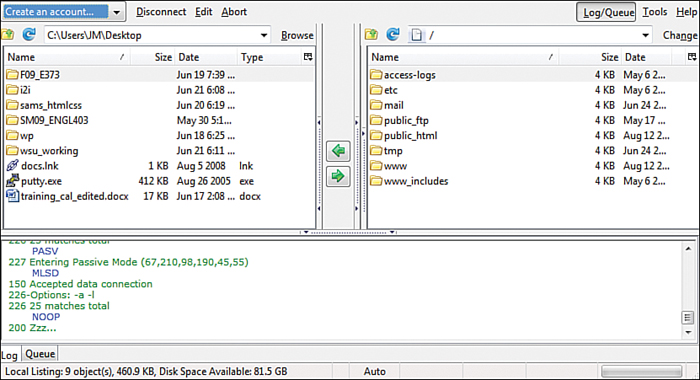
FIGURE 1.4 The FireFTP interface.
Many FTP clients are freely available to you, but you can also transfer files via the web-based File Manager tool that is likely part of your web server’s control panel. However, that method of file transfer typically introduces more steps into the process and isn’t nearly as streamlined (or simple) as the process of installing an FTP client on your own machine.
Here are some popular free FTP clients:
When you have selected an FTP client and installed it on your computer, you are ready to upload and download files from your web server. In the next section, you see how this process works using the sample file in Listing 1.1.
Video 1.1—How to Use FileZilla QuickConnect
The following steps show how to use Classic FTP to connect to your web server and transfer a file. However, all FTP clients use similar, if not exact, interfaces. If you understand the following steps, you should be able to use any FTP client.
Remember, you first need the hostname, the account username, and the account password.
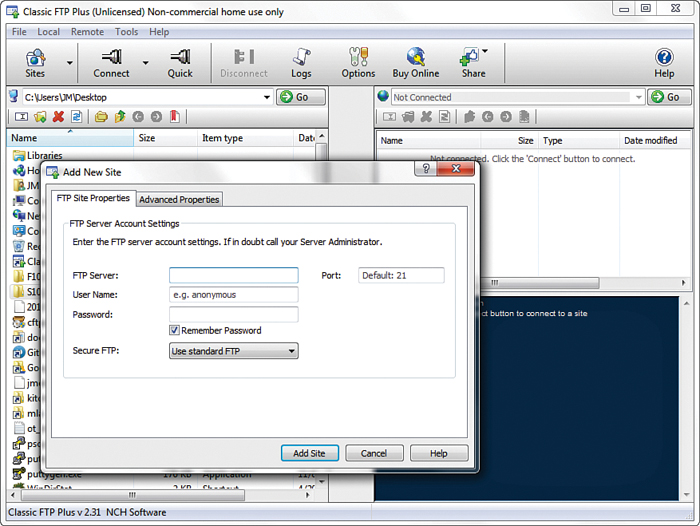
FIGURE 1.5 Connecting to a new site in Classic FTP.
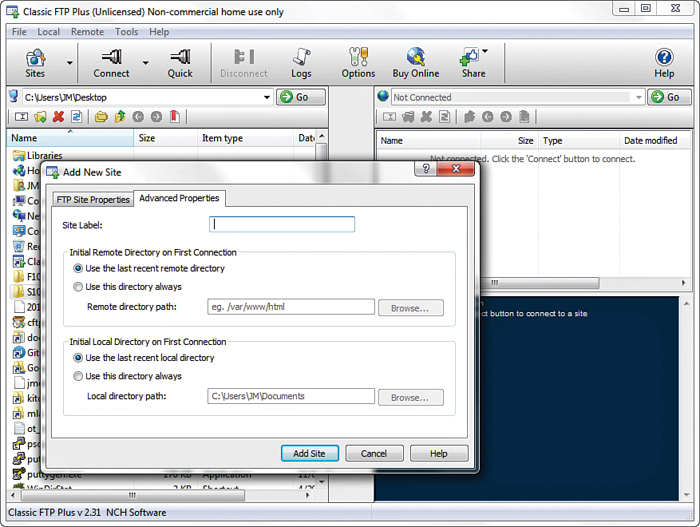
FIGURE 1.6 The Advanced connection options in ClassicFTP.
You will see a dialog box indicating that Classic FTP is attempting to connect to the web server. Upon successful connection, you will see an interface like the one in Figure 1.7, showing the contents of the local directory on the left and the contents of your web server on the right.
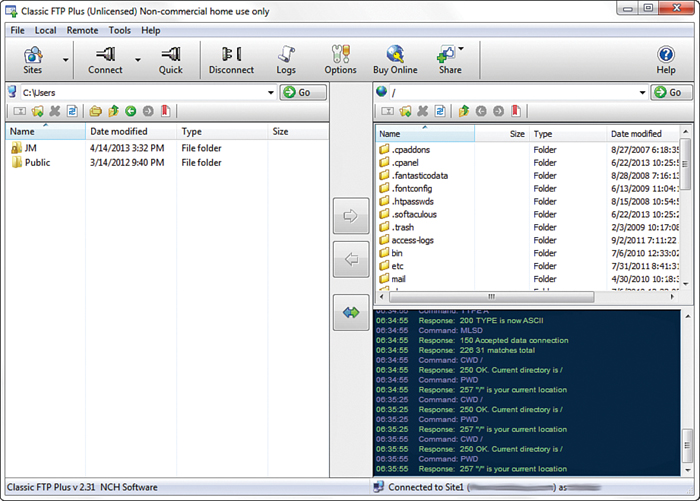
FIGURE 1.7 A successful connection to a remote web server via Classic FTP.
public_html, www (because www has been created as an alias for public_html), or htdocs. You do not have to create this directory; your hosting provider will have created it for you.
Double-click the document root directory name to open it. The display shown on the right of the FTP client interface changes to show the contents of this directory (it will probably be empty at this point, unless your web hosting provider has put placeholder files in that directory on your behalf).
sample.html file you created earlier from your computer to the web server. Find the file in the directory listing on the left of the FTP client interface (navigate, if you have to), and click it once to highlight the filename.These steps are conceptually similar to the steps you take anytime you want to send files to your web server via FTP. You can also use your FTP client to create subdirectories on the remote web server. To create a subdirectory using Classic FTP, click the Remote menu and then click New Folder. Different FTP clients have different interface options to achieve the same goal.
An important aspect of maintaining web content is determining how you will organize that content—not only for the user to find, but also for you to maintain on your server. Putting files in directories helps you manage those files.
Naming and organizing directories on your web server, and developing rules for file maintenance, is completely up to you. However, maintaining a well-organized server makes your management of its content more efficient in the long run.
As you browse the web, you might have noticed that URLs change as you navigate through websites. For instance, if you’re looking at a company’s website and you click on graphical navigation leading to the company’s products or services, the URL probably changes from
to
http://www.companyname.com/products/
or
http://www.companyname.com/services/
In the previous section, I used the term document root without really explaining what that is all about. The document root of a web server is essentially the trailing slash in the full URL. For instance, if your domain is yourdomain.com and your URL is http://www.yourdomain.com/, the document root is the directory represented by the trailing slash (/). The document root is the starting point of the directory structure you create on your web server; it is the place where the web server begins looking for files requested by the web browser.
If you put the sample.html file in your document root as previously directed, you will be able to access it via a web browser at the following URL:
http://www.yourdomain.com/sample.html
If you entered this URL into your web browser, you would see the rendered sample.html file, as shown in Figure 1.8.
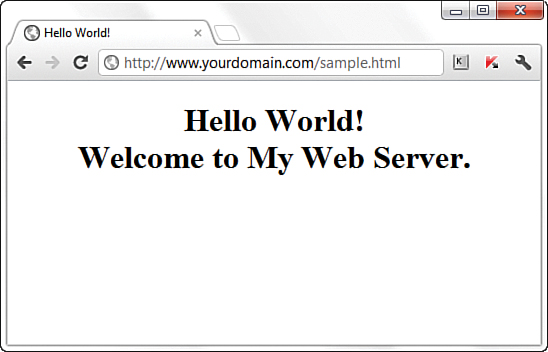
FIGURE 1.8 The sample.html file accessed via a web browser.
However, if you created a new directory within the document root and put the sample.html file in that directory, the file would be accessed at this URL:
http://www.yourdomain.com/newdirectory/sample.html
If you put the sample.html file in the directory you originally saw upon connecting to your server—that is, you did not change directories and place the file in the document root—the sample.html file would not be accessible from your web server at any URL. The file will still be on the machine that you know as your web server, but because the file is not in the document root—where the server software knows to start looking for files—it will never be accessible to anyone via a web browser.
The bottom line? Always navigate to the document root of your web server before you start transferring files.
This is especially true with graphics and other multimedia files. A common directory on web servers is called images, where, as you can imagine, all the image assets are placed for retrieval. Other popular directories include css for stylesheet files (if you are using more than one) and js for external JavaScript files. Alternatively, if you know that you will have an area on your website where visitors can download many different types of files, you might simply call that directory downloads.
Whether it’s a ZIP file containing your art portfolio or an Excel spreadsheet with sales numbers, it’s often useful to publish files on the Internet that aren’t simply web pages. To make available on the web a file that isn’t an HTML file, just upload the file to your website as if it were an HTML file, following the instructions earlier in this hour for uploading. After the file is uploaded to the web server, you can create a link to it (as you learn in Hour 8, “Using External and Internal Links”). In other words, your web server can serve much more than HTML.
Here’s a sample of the HTML code that you will learn more about later in this book. The following code would be used for a file named artfolio.zip, located in the downloads directory of your website, and link text that reads Download my art portfolio!:
<a href="/downloads/artfolio.zip">Download my art portfolio!</a>
Video 1.2—Using an Index Page
When you think of an index, you probably think of the section in the back of a book that tells you where to look for various keywords and topics. The index file in a web server directory can serve that purpose—if you design it that way. In fact, that’s where the name originates.
The index.html file (or just index file, as it’s usually referred to) is the name you give to the page you want people to see as the default file when they navigate to a specific directory in your website.
Another function of the index page is that users who visit a directory on your site that has an index page but who do not specify that page will still land on the main page for that section of your site—or for the site itself.
For instance, you can type either of the following URLs and land on Apple’s iPhone informational page:
http://www.apple.com/iphone/index.html
Had there been no index.html page in the iphone directory, the results would depend on the configuration of the web server. If the server is configured to disallow directory browsing, the user would have seen a “Directory Listing Denied” message when attempting to access the URL without a specified page name. However, if the server is configured to allow directory browsing, the user would have seen a list of the files in that directory.
Your hosting provider will already have determined these server configuration options. If your hosting provider enables you to modify server settings via a control panel, you can change these settings so that your server responds to requests based on your own requirements.
Not only is the index file used in subdirectories, but it’s used in the top-level directory (or document root) of your web site as well. The first page of your website—or home page or main page, or however you like to refer to the web content you want users to see when they first visit your domain—should be named index.html and placed in the document root of your web server. This ensures that when users type http://www.yourdomain.com/ into their web browsers, the server responds with the content you intended them to see (instead of “Directory Listing Denied” or some other unintended consequence).
Publishing HTML and multimedia files online is obviously the primary reason to learn HTML and create web content. However, there are also situations in which other forms of publishing simply aren’t viable. For example, you might want to distribute CD-ROMs, DVD-ROMs, or USB drives at a trade show with marketing materials designed as web content—that is, hyperlinked text viewable through a web browser, but without a web server involved. You might also want to include HTML-based instructional manuals on removable media for students at a training seminar. These are just two examples of how HTML pages can be used in publishing scenarios that don’t involve the Internet.
This process is also called creating local sites; even though there’s no web server involved, these bundles of hypertext content are still called sites. The local term comes into play because your files are accessed locally and not remotely (via a web server).
Let’s assume that you need to create a local site that you want to distribute on a USB drive. Even the cheapest USB drives hold so much data these days—and basic hypertext files are quite small—that you can distribute an entire site and a fully functioning web browser all on one little drive.
Simply think of the directory structure of your USB drive just as you would the directory structure of your web server. The top level of the USB drive directory structure can be your document root. Or if you are distributing a web browser along with the content, you might have two directories—for example, one named browser and one named content. In that case, the content directory would be your document root. Within the document root, you could have additional subfolders in which you place content and other multimedia assets.
Note
Distributing a web browser isn’t required when creating and distributing a local site, although it’s a nice touch. You can reasonably assume that users have their own web browsers and will open the index.html file in a directory to start browsing the hyperlinked content. However, if you want to distribute a web browser on the USB drive, go to http://www.portableapps.com/ and look for Portable Firefox or Portable Chrome.
It’s as important to maintain good organization with a local site, as it is with a remote website, so that you avoid broken links in your HTML files. You learn more about the specifics of linking together files in Hour 8, “Using External and Internal Links.”
You might have a blog hosted by a third party, such as WordPress, Tumblr, or Blogger, and thus have already published content without having a dedicated web server or even knowing any HTML. These services offer visual editors in addition to source editors, meaning that you can type your words and add presentational formatting such as bold, italics, or font colors without knowing the HTML for these actions. Still, the content becomes actual HTML when you click the Publish button in these editors.
However, with the knowledge you will acquire throughout this book, your blogging will be enhanced because you will able to use the source editor for your blog post content and blog templates, thus affording you more control over the look and feel of that content. These actions occur differently from the process you learned for creating an HTML file and uploading it via FTP to your own dedicated web server, but I would be remiss if I did not note that blogging is, in fact, a form of web publishing.
Whenever you transfer files to your web server or place them on removable media for local browsing, you should immediately test every page thoroughly. The following checklist helps ensure that your web content behaves the way you expected. Note that some of the terms might be unfamiliar to you at this point, but come back to this checklist as you progress through this book and create larger projects:
If your pages pass all those tests, you can rest easy; your site is ready for public viewing.
This hour introduced you to the concept of using HTML to mark up text files to produce web content. You also learned that there is more to web content than just the “page”—web content also includes image, audio, and video files. All this content lives on a web server—a remote machine often far from your own computer. On your computer or other device, you use a web browser to request, retrieve, and eventually display web content on your screen.
You learned the criteria to consider when determining whether a web hosting provider fits your needs. After you have selected a web hosting provider, you can begin to transfer files to your web server, which you also learned how to do, using an FTP client. You also learned a bit about web server directory structures and file management, as well as the very important purpose of the index.html file in a given web server directory. In addition, you learned that you can distribute web content on removable media, and you learned how to go about structuring the files and directories to achieve the goal of viewing content without using a remote web server.
Finally, you learned the importance of testing your work in multiple browsers after you’ve placed it on a web server. Writing valid, standards-compliant HTML and CSS helps ensure that your site looks reasonably similar for all visitors, but you still shouldn’t design without receiving input from potential users outside your development team—it is even more important to get input from others when you are a design team of one!
Q. I’ve looked at the HTML source of some web pages on the Internet, and it looks frighteningly difficult to learn. Do I have to think like a computer programmer to learn this stuff?
A. Although complex HTML pages can indeed look daunting, learning HTML is much easier than learning actual software programming languages (such as C++ or Java). HTML is a markup language rather than a programming language; you mark up text so that the browser can render the text a certain way. That’s a completely different set of thought processes than developing a computer program. You really don’t need any experience or skill as a computer programmer to be a successful web content author.
One of the reasons the HTML behind many commercial websites looks complicated is that it was likely created by a visual web design tool—a “what you see is what you get” (WYSIWYG) editor that uses whatever markup its software developer told it to use in certain circumstances (as opposed to being hand-coded, in which you are completely in control of the resulting markup). In this book, you are taught fundamental coding from the ground up, which typically results in clean, easy-to-read source code. Visual web design tools have a knack for making code difficult to read and for producing code that is convoluted and not standards compliant.
Q. Running all the tests you recommend would take longer than creating my pages! Can’t I get away with less testing?
A. If your pages aren’t intended to make money or provide an important service, it’s probably not a big deal if they look funny to some users or produce errors once in a while. In that case, just test each page with a couple different browsers and call it a day. However, if you need to project a professional image, there is no substitute for rigorous testing.
Q. Seriously, who cares how I organize my web content?
A. Believe it or not, the organization of your web content does matter to search engines and potential visitors to your site. But overall, having an organized web server directory structure helps you keep track of content that you are likely to update frequently. For instance, if you have a dedicated directory for images or multimedia, you know exactly where to look for a file you want to update—no need to hunt through directories containing other content.
sample.html file into another file named index.html, change the text between the <title> and </title> tags to something new, and change the text between the <h1> and </h1> tags to something new. Save the file and upload it to the new subdirectory. Use your web browser to navigate to the new directory on your web server, and see that the content in the index.html file appears. Then, using your FTP client, delete the index.html file from the remote subdirectory. Return to that URL with your web browser, reload the page, and see how the server responds without the index.html file in place.
{kind=link}