
At the core of most large-scale applications and services is a high-performance data storage solution. The back-end data store is responsible for storing important data such as user account information, product data, accounting information, and blogs. Good applications require the capability to store and retrieve data with accuracy, speed, and reliability. Therefore, the data storage mechanism you choose must be capable of performing at a level that satisfies your application’s demand.
Several data storage solutions are available to store and retrieve the data your applications need. The three most common are direct file system storage in files, relational databases, and NoSQL databases. The NoSQL data store chosen for this book is MongoDB because it is the most widely used and the most versatile.
The following sections describe NoSQL and MongoDB and discuss the design considerations to review before deciding how to implement the structure of data and the database configuration. The sections cover the questions to ask and then address the mechanisms built into MongoDB that satisfy the resulting demands.
A common misconception is that the term NoSQL stands for “No SQL.” NoSQL actually stands for “Not only SQL,” to emphasize the fact that NoSQL databases are an alternative to SQL and can, in fact, apply SQL-like query concepts.
NoSQL covers any database that is not a traditional relational database management system (RDBMS). The motivation behind NoSQL is mainly simplified design, horizontal scaling, and finer control over the availability of data. NoSQL databases are more specialized for types of data, which makes them more efficient and better performing than RDBMS servers in most instances.
NoSQL seeks to break away from the traditional structure of relational databases, and enable developers to implement models in ways that more closely fit the data flow needs of their system. This means that NoSQL databases can be implemented in ways that traditional relational databases could never be structured.
Several different NoSQL technologies exist, including the HBase column structure, the Redis key/value structure, and the Virtuoso graph structure. However, this book uses MongoDB and the document model because of the great flexibility and scalability offered in implementing back-end storage for web applications and services. In addition, MongoDB is by far the most popular and well-supported NoSQL language currently available. The following sections describe some of the NoSQL database types.
Document store databases apply a document-oriented approach to storing data. The idea is that all the data for a single entity can be stored as a document, and documents can be stored together in collections.
A document can contain all the necessary information to describe an entity. This includes the capability to have subdocuments, which in RDBMS are typically stored as an encoded string or in a separate table. Documents in the collection are accessed via a unique key.
The simplest type of NoSQL database is the key-value stores. These databases store data in a completely schema-less way, meaning that no defined structure governs what is being stored. A key can point to any type of data, from an object, to a string value, to a programming language function.
The advantage of key-value stores is that they are easy to implement and add data to. That makes them great to implement as simple storage for storing and retrieving data based on a key. The downside is that you cannot find elements based on the stored values.
Column store databases store data in columns within a key space. The key space is based on a unique name, value, and timestamp. This is similar to the key-value databases; however, column store databases are geared toward data that uses a timestamp to differentiate valid content from stale content. This provides the advantage of applying aging to the data stored in the database.
Graph store databases are designed for data that can be easily represented as a graph. This means that elements are interconnected with an undetermined number of relations between them, as in examples such as family and social relations, airline route topology, or a standard road map.
When investigating NoSQL databases, keep an open mind regarding which database to use and how to apply it. This is especially true with high-performance systems.
You might need to implement a strategy based on only RDBMS or NoSQL—or you might find that a combination of the two offers the best solution in the end.
With all high-performance databases, you will find yourself trying to balance speed, accuracy, and reliability. The following is a list of just some considerations when choosing a database:
MongoDB is an agile and scalable NoSQL database. The name Mongo comes from the word humongous. MongoDB is based on the NoSQL document store model, in which data objects are stored as separate documents inside a collection instead of in the traditional columns and rows of a relational database. The documents are stored as binary JSON or BSON objects.
The motivation of the MongoDB language is to implement a data store that provides high performance, high availability, and automatic scaling. MongoDB is extremely simple to install and implement, as you will see in upcoming hours. MongoDB offers great website back-end storage for high-traffic websites that need to store data such as user comments, blogs, or other items because it is fast, scalable, and easy to implement.
The following are some additional reasons MongoDB has become the most popular NoSQL database:
MongoDB groups data through collections. A collection is simply a grouping of documents that have the same or a similar purpose. A collection acts similarly to a table in a traditional SQL database. However, it has a major difference: In MongoDB, a collection is not enforced by a strict schema. Instead, documents in a collection can have a slightly different structure from one another, as needed. This reduces the need to break items in a document into several different tables, as is often done in SQL implementations.
A document is a representation of a single entity of data in the MongoDB database. A collection consists of one or more related objects. A major difference exists between MongoDB and SQL, in that documents are different from rows. Row data is flat, with one column for each value in the row. However, in MongoDB, documents can contain embedded subdocuments, providing a much closer inherent data model to your applications.
In fact, the records in MongoDB that represent documents are stored as BSON, a lightweight binary form of JSON. It uses field:value pairs that correspond to JavaScript property:value pairs that define the values stored in the document. Little translation is necessary to convert MongoDB records back into JSON strings that you might be using in your application.
For example, a document in MongoDB might be structured similar to the following, with name, version, languages, admin, and paths fields:
{
name: "New Project",
version: 1,
languages: ["JavaScript", "HTML", "CSS"],
admin: {name: "Brad", password: "****"},
paths: {temp: "/tmp", project:"/opt/project", html: "/opt/project/html"}
}
Notice that the document structure contains fields/properties that are strings, integers, arrays, and objects, just as in a JavaScript object. Table 1.1 lists the different data types for field values in the BSON document.
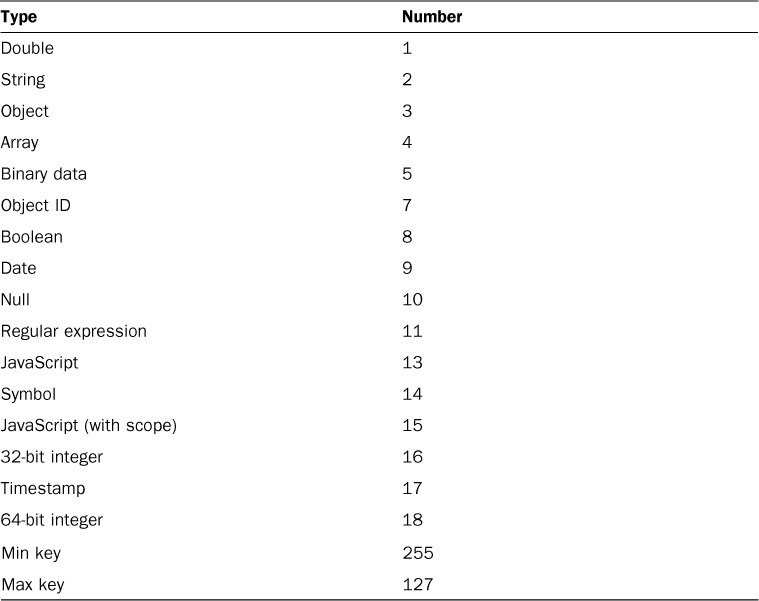
TABLE 1.1 MongoDB Data Types and Corresponding ID Number
The field names cannot contain null characters, dots (.), or dollar signs ($). In addition, the _id field name is reserved for the Object ID. The _id field is a unique ID for the system that consists of the following parts:
The maximum size of a document in MongoDB is 16MB, to prevent queries that result in an excessive amount of RAM or intensive hits to the file system. You might never come close to this, but you still need to keep the maximum document size in mind when designing some complex data types that contain file data into your system.
The BSON data format provides several different types used when storing the JavaScript objects to binary form. These types match the JavaScript type as closely as possible. It is important to understand these types because you can actually query MongoDB to find objects that have a specific property with a value of a certain type. For example, you can look for documents in a database whose timestamp value is a String object or query for ones whose timestamp is a Date object.
MongoDB assigns each data type of an integer ID number from 1 to 255 when querying by type. Table 1.1 lists the data types MongoDB supports, along with the number MongoDB uses to identify them.
Another point to be aware of when working with the different data types in MongoDB is the order in which they are compared when querying to find and update data. When comparing values of different BSON types, MongoDB uses the following comparison order, from lowest to highest:
1. Min key (internal type)
2. Null
3. Numbers (32-bit integer, 64-bit integer, double)
4. Symbol, String
5. Object
6. Array
7. Binary data
8. Object ID
9. Boolean
10. Date, timestamp
11. Regular expression
12. Max key (internal type)
Before you begin implementing a MongoDB database, you need to understand the nature of the data being stored, how that data will be stored, and how it will be accessed. Understanding these concepts helps you make determinations ahead of time and structure the data and your application for optimal performance.
Specifically, you should ask yourself the following questions:
When you have the answers to these questions, you are ready to consider the structure of collections and documents inside MongoDB. The following sections discuss different methods of document, collection, and database modeling you can use in MongoDB to optimize data storage and access.
Data normalization is the process of organizing documents and collections to minimize redundancy and dependency. This is done by identifying object properties that are subobjects and that should be stored as a separate document in another collection from the object’s document. Typically, this is useful for objects that have a one-to-many or many-to-many relationship with subobjects.
The advantage of normalizing data is that the database size will be smaller because only a single copy of objects will exist in their own collection instead of being duplicated on multiple objects in single collection. Additionally, if you modify the information in the subobject frequently, then you need to modify only a single instance instead of every record in the object’s collection that has that subobject.
A major disadvantage of normalizing data is that, when looking up user objects that require the normalized subobject, a separate lookup must occur to link the subobject. This can result in a significant performance hit if you are accessing the user data frequently.
An example of when normalizing data makes sense is a system that contains users who have a favorite store. Each User is an object with name, phone, and favoriteStore properties. The favoriteStore property is also a subobject that contains name, street, city, and zip properties.
However, thousands of users might have the same favorite store, so you see a high one-to-many relationship. Therefore, storing the FavoriteStore object data in each User object doesn’t make sense because it would result in thousands of duplications. Instead, the FavoriteStore object should include an _id object property that can be referenced from documents in the user’s stores collection. The application can then use the reference ID favoriteStore to link data from the Users collection to FavoriteStore documents in the FavoriteStores collection.
Figure 1.1 illustrates the structure of the Users and FavoriteStores collections just described.
FIGURE 1.1 Defining normalized MongoDB documents by adding a reference to documents in another collection.
Denormalizing data is the process of identifying subobjects of a main object that should be embedded directly into the document of the main object. Typically, this is done on objects that have mostly one-to-one relationships or that are relatively small and do not get updated frequently.
The major advantage of denormalized documents is that you can get the full object back in a single lookup without needing to do additional lookups to combine subobjects from other collections. This is a major performance enhancement. The downside is that, for subobjects with a one-to-many relationship, you are storing a separate copy in each document; this slows insertion a bit and takes up additional disk space.
An example of when normalizing data makes sense is a system that contains users’ home and work contact information. The user is an object represented by a User document with name, home, and work properties. The home and work properties are subobjects that contain phone, street, city, and zip properties.
The home and work properties do not change often for the user. Multiple users might reside in the same home, but this likely will be a small number. In addition, the actual values inside the subobjects are not that big and will not change often. Therefore, storing the home contact information directly in the User object makes sense.
The work property takes a bit more thinking. How many people are you really going to get who have the same work contact information? If the answer is not many, the work object should be embedded with the User object. How often are you querying the User and need the work contact information? If you will do so rarely, you might want to normalize work into its own collection. However, if you will do so frequently or always, you will likely want to embed work with the User object.
Figure 1.2 illustrates the structure of Users with the home and work contact information embedded, as described previously.
FIGURE 1.2 Defining denormalized MongoDB documents by implementing embedded objects inside a document.
A great feature of MongoDB is the capability to create a capped collection. A capped collection is a collection that has a fixed size. When a new document needs to be written to a collection that exceeds the size of the collection, the oldest document in the collection is deleted and the new document is inserted. Capped collections work great for objects that have a high rate of insertion, retrieval, and deletion.
The following list highlights the benefits of using capped collections:
Capped collections do impose the following restrictions:
A great use of capped collections is as a rolling log of transactions in your system. You can always access the last X number of log entries without needing to explicitly clean up the oldest.
Write operations are atomic at the document level in MongoDB. Thus, only one process can be updating a single document or a single collection at the same time. This means that writing to documents that are denormalized is atomic. However, writing to documents that are normalized requires separate write operations to subobjects in other collections; therefore, the write of the normalized object might not be atomic as a whole.
You need to keep atomic writes in mind when designing your documents and collections to ensure that the design fits the needs of the application. In other words, if you absolutely must write all parts of an object as a whole in an atomic manner, you need to design the object in a denormalized way.
When you update a document, you must consider what effect the new data will have on document growth. MongoDB provides some padding in documents to allow for typical growth during an update operation. However, if the update causes the document to grow to a size that exceeds the allocated space on disk, MongoDB must relocate that document to a new location on the disk, incurring a performance hit on the system. Frequent document relocation also can lead to disk fragmentation issues. For example, if a document contains an array and you add enough elements to the array to exceed the space allocated, the object needs to be moved to a new location on disk.
One way to mitigate document growth is to use normalized objects for properties that can grow frequently. For example instead of using an array to store items in a Cart object, you could create a collection for CartItems; then you could store new items that get placed in the cart as new documents in the CartItems collection and reference the user’s cart item within them.
MongoDB provides several mechanisms to optimize performance, scale, and reliability. As you are contemplating your database design, consider the following options:
_id property of a collection is automatically indexed on because looking up items by ID is common practice. However, you also need to consider other ways users access data and implement indexes that enhance those lookup methods as well.Another important consideration when designing your MongoDB documents and collections is the number of collections the design will result in. Having a large number of collections doesn’t result in a significant performance hit, but having many items in the same collection does. Consider ways to break up your larger collections into more consumable chunks.
An example of this is storing a history of user transactions in the database for past purchases. You recognize that, for these completed purchases, you will never need to look them up together for multiple users. You need them available only for users to look at their own history. If you have thousands of users who have a lot of transactions, storing those histories in a separate collection for each user makes sense.
One of the most commonly overlooked aspects of database design is the data life cycle. How long should documents exist in a specific collection? Some collections have documents that should be kept indefinitely (for example, active user accounts). However, keep in mind that each document in the system incurs a performance hit when querying a collection. You should define a Time To Live (TTL) value for documents in each of your collections.
You can implement a TTL mechanism in MongoDB in several ways. One method is to implement code in your application to monitor and clean up old data. Another method is to utilize the MongoDB TTL setting on a collection, to define a profile in which documents are automatically deleted after a certain number of seconds or at a specific clock time.
Another method for keeping collections small when you need only the most recent documents is to implement a capped collection that automatically keeps the size of the collection small.
The final point to consider—and even reconsider—is data usability and performance. Ultimately, these are the two most important aspects of any web solution and, consequently, the storage behind it.
Data usability describes the capability of the database to satisfy the functionality of the website. You need to make certain first that the data can be accessed so that the website functions correctly. Users will not tolerate a website that does not do what they want it to. This also includes the accuracy of the data.
Then you can consider performance. Your database must deliver the data at a reasonable rate. You can consult the previous sections when evaluating and designing the performance factors for your database.
In some more complex circumstances, you might find it necessary to evaluate data usability, then consider performance, and then look back to usability in a few cycles until you get the balance correct. Also keep in mind that, in today’s world, usability requirements can change at any time. Be sure to design your documents and collections so that they can become more scalable in the future, if necessary.
At the core of most large-scale web applications and services is a high-performance data storage solution. The back-end data store is responsible for storing everything from user account information, to shopping cart items, to blog and comment data. Good web applications require the capability to store and retrieve data with accuracy, speed, and reliability. Therefore, the data storage mechanism you choose must perform at a level to satisfy user demand.
Several data storage solutions are available to store and retrieve data your web applications need. The three most common are direct file system storage in files, relational databases, and NoSQL databases. The data store chosen for this book is MongoDB, which is a NoSQL database.
In this hour, you learned about the design considerations to review before deciding how to implement the structure of data and configuration of a MongoDB database. You also learned which design questions to ask and then how to explore the mechanisms built into MongoDB to answer those questions.
Q. What types of distributions are available for MongoDB?
A. General distributions for MongoDB support Windows, Linux, Mac OS X, and Solaris. Enterprise subscriptions also are available for professional and commercial applications that require enterprise-level capabilities, uptime, and support. If the MongoDB data is critical to your application and you have a high amount of DB traffic, you might want to consider the paid subscription route. For information on the subscription, go to https://www.mongodb.com/products/mongodb-subscriptions.
Q. Does MongoDB have a schema?
A. Sort of. MongoDB implements dynamic schemas, enabling you to create collections without having to define the structure of the documents. This means you can store documents that do not have identical fields.