For Clancy, my favorite enemy within.
A great number of people helped bring this book into existence. Some contributed ideas for technical topics, some helped with the process of producing the book, and some just made life more fun while I was working on
When the number of contributors to a book is large, it is not uncommon to dispense with individual acknowledgments in favor of a generic "Contributors to this book are too numerous to mention." I prefer to follow the expansive lead of John L. Hennessy and David A. Patterson in
With the exception of direct quotations, all the words in this book are mine. However, many of the ideas I discuss came from others. I have done my best to keep track of who contributed what, but I know I have included information from sources I now fail to recall, foremost among them many posters to the Usenet newsgroups comp.lang.c++
Many ideas in the C++ community have been developed independently by many people. In what follows, I note only where I was exposed to particular ideas, not necessarily where those ideas
Brian Kernighan suggested the use of macros to approximate the syntax of the new C++ casting operators I describe in Item 2.
In Item 3, my warning about deleting an array of derived class objects through a base class pointer is based on material in Dan Saks' "Gotchas" talk, which he's given at several conferences and trade
In Item 5, the proxy class technique for preventing unwanted application of single-argument constructors is based on material in Andrew Koenig's column in the January 1994
James Kanze made a posting to comp.lang.c++
David Cok, writing me about material I covered in operator new and the new operator that is the crux of Item 8. Even after reading his letter, I didn't really understand the distinction, but without his initial prodding, I probably still
The notion of using destructors to prevent resource leaks (used in Item 9) comes from section 15.3 of Margaret A. Ellis' and Bjarne Stroustrup's
Some of my discussion in Item 11 was inspired by material in Chapter 4 of
My description of over-eager memory allocation for the DynArray class in Item 18 is based on Tom Cargill's article, "A Dynamic vector is harder than it looks," in the June 1992
Item 21 was inspired by Brian Kernighan's paper, "An AWK to C++ Translator," at the 1991 USENIX C++ Conference. His use of overloaded operators (sixty-seven of them!) to handle mixed-type arithmetic operations, though designed to solve a problem unrelated to the one I explore in Item 21, led me to consider multiple overloadings as a solution to the problem of temporary
In Item 26, my design of a template class for counting objects is based on a posting to comp.lang.c++
The idea of a mixin class to keep track of pointers from operator new (see Item 27) is based on a suggestion by Don Box. Steve Clamage made the idea practical by explaining how dynamic_cast can be used to find the beginning of memory for an
The discussion of smart pointers in Item 28 is based in part on Steven Buroff's and Rob Murray's C++ Oracle column in the October 1993
In Item 29, the use of a base class to store reference counts and of smart pointers to manipulate those counts is based on Rob Murray's discussions of the same topics in sections 6.3.2 and 7.4.2, respectively, of his
In Item 30, my discussion of lvalue contexts is based on comments in Dan Saks' column in the C User's Journal
The use of runtime type information to build vtbl-like arrays of function pointers (in Item 31) is based on ideas put forward by Bjarne Stroustrup in postings to comp.lang.c++
The material in Item 33 is based on several of my dynamic_cast to implement a virtual operator= that detects arguments of the wrong
Much of the material in Item 34 was motivated by Steve Clamage's article, "Linking C++ with other languages," in the May 1992 strdup was motivated by an anonymous
Reviewing draft copies of a book is hard — and vitally important — work. I am grateful that so many people were willing to invest their time and energy on my behalf. I am especially grateful to Jill Huchital, Tim Johnson, Brian Kernighan, Eric Nagler, and Chris Van Wyk, as they read the book (or large portions of it) more than once. In addition to these gluttons for punishment, complete drafts of the manuscript were read by Katrina Avery, Don Box, Steve Burkett, Tom Cargill, Tony Davis, Carolyn Duby, Bruce Eckel, Read Fleming, Cay Horstmann, James Kanze, Russ Paielli, Steve Rosenthal, Robin Rowe, Dan Saks, Chris Sells, Webb Stacy, Dave Swift, Steve Vinoski, and Fred Wild. Partial drafts were reviewed by Bob Beauchaine, Gerd Hoeren, Jeff Jackson, and Nancy L. Urbano. Each of these reviewers made comments that greatly improved the accuracy, utility, and presentation of the material you find
Once the book came out, I received corrections and suggestions from many people. I've listed these sharp-eyed readers in the order in which I received their missives: Luis Kida, John Potter, Tim Uttormark, Mike Fulkerson, Dan Saks, Wolfgang Glunz, Clovis Tondo, Michael Loftus, Liz Hanks, Wil Evers, Stefan Kuhlins, Jim McCracken, Alan Duchan, John Jacobsma, Ramesh Nagabushnam, Ed Willink, Kirk Swenson, Jack Reeves, Doug Schmidt, Tim Buchowski, Paul Chisholm, Andrew Klein, Eric Nagler, Jeffrey Smith, Sam Bent, Oleg Shteynbuk, Anton Doblmaier, Ulf Michaelis, Sekhar Muddana, Michael Baker, Yechiel Kimchi, David Papurt, Ian Haggard, Robert Schwartz, David Halpin, Graham Mark, David Barrett, Damian Kanarek, Ron Coutts, Lance Whitesel, Jon Lachelt, Cheryl Ferguson, Munir Mahmood, Klaus-Georg Adams, David Goh, Chris Morley, and Rainer Baumschlager. Their suggestions allowed me to improve More Effective C++ in updated printings (such as this one), and I greatly appreciate their
During preparation of this book, I faced many questions about the emerging
John Max Skaller and Steve Rumsby conspired to get me the HTML for the draft ANSI C++ standard before it was widely available. Vivian Neou pointed me to the
Bryan Hobbs and Hachemi Zenad generously arranged to get me a copy of the internal engineering version of the
Without the staff at the Corporate and Professional Publishing Division of Addison-Wesley, there would be no book, and I am indebted to Kim Dawley, Lana Langlois, Simone Payment, Marty Rabinowitz, Pradeepa Siva, John Wait, and the rest of the staff for their encouragement, patience, and help with the production of this
Chris Guzikowski helped draft the back cover copy for this book, and Tim Johnson stole time from his research on low-temperature physics to critique later versions of that
Tom Cargill graciously agreed to make his
Kathy Reed was responsible for my introduction to programming; surely she didn't deserve to have to put up with a kid like me. Donald French had faith in my ability to develop and present C++ teaching materials when I had no track record. He also introduced me to John Wait, my editor at Addison-Wesley, an act for which I will always be grateful. The triumvirate at Beaver Ridge — Jayni Besaw, Lorri Fields, and Beth McKee — provided untold entertainment on my breaks as I worked on the
My wife, Nancy L. Urbano, put up with me and put up with me and put up with me as I worked on the book, continued to work on the book, and kept working on the book. How many times did she hear me say we'd do something after the book was done? Now the book is done, and we will do those things. She amazes me. I love
Finally, I must acknowledge our puppy,
These are heady days for C++ programmers. Commercially available less than a decade, C++ has nevertheless emerged as the language of choice for systems programming on nearly all major computing platforms. Companies and individuals with challenging programming problems increasingly embrace the language, and the question faced by those who do not use C++ is often when they will start, not if. Standardization of C++ is complete, and the breadth and scope of the accompanying library — which both dwarfs and subsumes that of C — makes it possible to write rich, complex programs without sacrificing portability or implementing common algorithms and data structures from scratch. C++ compilers continue to proliferate, the features they offer continue to expand, and the quality of the code they generate continues to improve. Tools and environments for C++ development grow ever more abundant, powerful, and robust. Commercial libraries all but obviate the need to write code in many application
As the language has matured and our experience with it has increased, our needs for information about it have changed. In 1990, people wanted to know what C++ was. By 1992, they wanted to know how to make it work. Now C++ programmers ask higher-level questions: How can I design my software so it will adapt to future demands? How can I improve the efficiency of my code without compromising its correctness or making it harder to use? How can I implement sophisticated functionality not directly supported by the
In this book, I answer these questions and many others like
This book shows how to design and implement C++ software that is more effective: more likely to behave correctly; more robust in the face of exceptions; more efficient; more portable; makes better use of language features; adapts to change more gracefully; works better in a mixed-language environment; is easier to use correctly; is harder to use incorrectly. In short, software that's just better.
The material in this book is divided into 35 Items. Each Item summarizes accumulated wisdom of the C++ programming community on a particular topic. Most Items take the form of guidelines, and the explanation accompanying each guideline describes why the guideline exists, what happens if you fail to follow it, and under what conditions it may make sense to violate the guideline
Items fall into several categories. Some concern particular language features, especially newer features with which you may have little experience. For example, Items 9 through 15 are devoted to exceptions (as are the magazine articles by Tom Cargill, Jack Reeves, and Herb Sutter). Other Items explain how to combine the features of the language to achieve higher-level goals. Items 25 through 31, for instance, describe how to constrain the number or placement of objects, how to create functions that act "virtual" on the type of more than one object, how to create "smart pointers," and more. Still other Items address broader topics; Items 16 through 24 focus on efficiency. No matter what the topic of a particular Item, each takes a no-nonsense approach to the subject. In More Effective C++, you learn how to use C++ more effectively. The descriptions of language features that make up the bulk of most C++ texts are in this book mere background
An implication of this approach is that you should be familiar with C++ before reading this book. I take for granted that you understand classes, protection levels, virtual and nonvirtual functions, etc., and I assume you are acquainted with the concepts behind templates and exceptions. At the same time, I don't expect you to be a language expert, so when poking into lesser-known corners of C++, I always explain what's going
The C++ I describe in this book is the language specified by the
I recognize that just because the standardization committee blesses a feature or endorses a practice, there's no guarantee that the feature is present in current compilers or the practice is applicable to existing environments. When faced with a discrepancy between theory (what the committee says) and practice (what actually works), I discuss both, though my bias is toward things that work. Because I discuss both, this book will aid you as your compilers approach conformance with the standard. It will show you how to use existing constructs to approximate language features your compilers don't yet support, and it will guide you when you decide to transform workarounds into newly- supported
Notice that I refer to your compilers — plural. Different compilers implement varying approximations to the standard, so I encourage you to develop your code under at least two compilers. Doing so will help you avoid inadvertent dependence on one vendor's proprietary language extension or its misinterpretation of the standard. It will also help keep you away from the bleeding edge of compiler technology, e.g., from new features supported by only one vendor. Such features are often poorly implemented (buggy or slow — frequently both), and upon their introduction, the C++ community lacks experience to advise you in their proper use. Blazing trails can be exciting, but when your goal is producing reliable code, it's often best to let others test the waters before jumping
There are two constructs you'll see in this book that may not be familiar to you. Both are relatively recent language extensions. Some compilers support them, but if your compilers don't, you can easily approximate them with features you do
The first construct is the bool type, which has as its values the keywords true and false. If your compilers haven't implemented bool, there are two ways to approximate it. One is to use a global
enum bool { false, true };
This allows you to overload functions on the basis of whether they take a bool or an int, but it has the disadvantage that the built-in comparison operators (i.e., ==, <, >=, etc.) still return ints. As a result, code like the following will not behave the way it's supposed
void f(int); void f(bool);
int x, y;
...
f( x < y ); // calls f(int), but it
// should call f(bool)
The enum approximation may thus lead to code whose behavior changes when you submit it to a compiler that truly supports bool.
An alternative is to use a typedef for bool and constant objects for true and false:
typedef int bool;
const bool false = 0; const bool true = 1;
This is compatible with the traditional semantics of C and C++, and the behavior of programs using this approximation won't change when they're ported to bool-supporting compilers. The drawback is that you can't differentiate between bool and int when overloading functions. Both approximations are reasonable. Choose the one that best fits your
The second new construct is really four constructs, the casting forms static_cast, const_cast, dynamic_cast, and reinterpret_cast. If you're not familiar with these casts, you'll want to turn to Item 2 and read all about them. Not only do they do more than the C-style casts they replace, they do it better. I use these new casting forms whenever I need to perform a cast in this
There is more to C++ than the language itself. There is also the standard library (see Item E49). Where possible, I employ the standard string type instead of using raw char* pointers, and I encourage you to do the same. string objects are no more difficult to manipulate than char*-based strings, and they relieve you of most memory-management concerns. Furthermore, string objects are less susceptible to memory leaks if an exception is thrown (see Items 9 and 10). A well-implemented string type can hold its own in an efficiency contest with its char* equivalent, and it may even do better. (For insight into how this could be, see Item 29.) If you don't have access to an implementation of the standard string type, you almost certainly have access to some string-like class. Use it. Just about anything is preferable to raw char*s.
I use data structures from the standard library whenever I can. Such data structures are drawn from the Standard Template Library (the "STL" — see Item 35). The STL includes bitsets, vectors, lists, queues, stacks, maps, sets, and more, and you should prefer these standardized data structures to the ad hoc equivalents you might otherwise be tempted to write. Your compilers may not have the STL bundled in, but don't let that keep you from using it. Thanks to Silicon Graphics, you can download a free copy that works with many compilers from the
If you currently use a library of algorithms and data structures and are happy with it, there's no need to switch to the STL just because it's "standard." However, if you have a choice between using an STL component or writing your own code from scratch, you should lean toward using the STL. Remember code reuse? STL (and the rest of the standard library) has lots of code that is very much worth
Any time I mention inheritance in this book, I mean public inheritance (see Item E35). If I don't mean public inheritance, I'll say so explicitly. When drawing inheritance hierarchies, I depict base-derived relationships by drawing arrows from derived classes to base classes. For example, here is a hierarchy from Item 31:
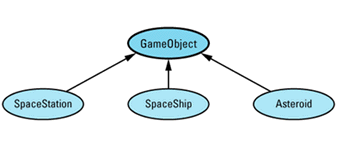
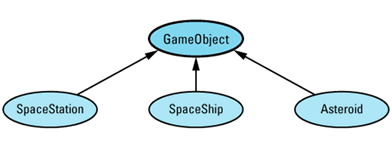
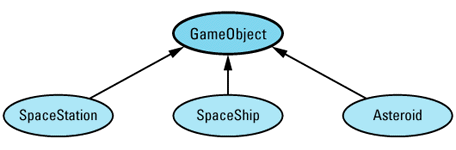
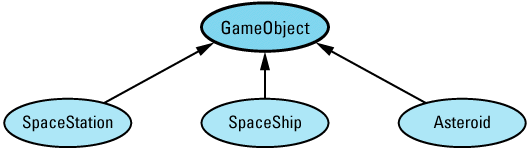
This notation is the reverse of the convention I employed in the first (but not the second) edition of Effective C++. I'm now convinced that most C++ practitioners draw inheritance arrows from derived to base classes, and I am happy to follow suit. Within such diagrams, abstract classes (e.g., GameObject) are shaded and concrete classes (e.g., SpaceShip) are
Inheritance gives rise to pointers and references with two different types, a static type and a dynamic type. The static type of a pointer or reference is its declared type. The dynamic type is determined by the type of object it actually refers to. Here are some examples based on the classes
GameObject *pgo = // static type of pgo is
new SpaceShip; // GameObject*, dynamic
// type is SpaceShip*
Asteroid *pa = new Asteroid; // static type of pa is
// Asteroid*. So is its
// dynamic type
pgo = pa; // static type of pgo is
// still (and always)
// GameObject*. Its
// dynamic type is now
// Asteroid*
GameObject& rgo = *pa; // static type of rgo is
// GameObject, dynamic
// type is Asteroid
These examples also demonstrate a naming convention I like. pgo is a pointer-to-GameObject; pa is a pointer-to-Asteroid; rgo is a reference-to-GameObject. I often concoct pointer and reference names in this
Two of my favorite parameter names are lhs and rhs, abbreviations for "left-hand side" and "right-hand side," respectively. To understand the rationale behind these names, consider a class for representing rational
class Rational { ... };
If I wanted a function to compare pairs of Rational objects, I'd declare it like
bool operator==(const Rational& lhs, const Rational& rhs);
That would let me write this kind of
Rational r1, r2;
...
if (r1 == r2) ...
Within the call to operator==, r1 appears on the left-hand side of the "==" and is bound to lhs, while r2 appears on the right-hand side of the "==" and is bound to rhs.
Other abbreviations I employ include ctor for "constructor," dtor for "destructor," and RTTI for C++'s support for runtime type identification (of which dynamic_cast is the most commonly used
When you allocate memory and fail to free it, you have a memory leak. Memory leaks arise in both C and C++, but in C++, memory leaks leak more than just memory. That's because C++ automatically calls constructors when objects are created, and constructors may themselves allocate resources. For example, consider this
class Widget { ... }; // some class — it doesn't
// matter what it is
Widget *pw = new Widget; // dynamically allocate a
// Widget object
... // assume pw is never
// deleted
This code leaks memory, because the Widget pointed to by pw is never deleted. However, if the Widget constructor allocates additional resources that are to be released when the Widget is destroyed (such as file descriptors, semaphores, window handles, database locks, etc.), those resources are lost just as surely as the memory is. To emphasize that memory leaks in C++ often leak other resources, too, I usually speak of resource leaks in this book rather than memory
You won't see many inline functions in this book. That's not because I dislike inlining. Far from it, I believe that inline functions are an important feature of C++. However, the criteria for determining whether a function should be inlined can be complex, subtle, and platform-dependent (see Item E33). As a result, I avoid inlining unless there is a point about inlining I wish to make. When you see a non-inline function in More Effective C++, that doesn't mean I think it would be a bad idea to declare the function inline, it just means the decision to inline that function is independent of the material I'm examining at that point in the
A few C++ features have been deprecated by the
A client is somebody (a programmer) or something (a class or function, typically) that uses the code you write. For example, if you write a Date class (for representing birthdays, deadlines, when the Second Coming occurs, etc.), anybody using that class is your client. Furthermore, any sections of code that use the Date class are your clients as well. Clients are important. In fact, clients are the name of the game! If nobody uses the software you write, why write it? You will find I worry a lot about making things easier for clients, often at the expense of making things more difficult for you, because good software is "clientcentric" — it revolves around clients. If this strikes you as unreasonably philanthropic, view it instead through a lens of self-interest. Do you ever use the classes or functions you write? If so, you're your own client, so making things easier for clients in general also makes them easier for
When discussing class or function templates and the classes or functions generated from them, I reserve the right to be sloppy about the difference between the templates and their instantiations. For example, if Array is a class template taking a type parameter T, I may refer to a particular instantiation of the template as an Array, even though Array<T> is really the name of the class. Similarly, if swap is a function template taking a type parameter T, I may refer to an instantiation as swap instead of swap<T>. In cases where this kind of shorthand might be unclear, I include template parameters when referring to template
Reporting Bugs, Making Suggestions, Getting Book Updates
I have tried to make this book as accurate, readable, and useful as possible, but I know there is room for improvement. If you find an error of any kind — technical, grammatical, typographical, whatever — please tell me about it. I will try to correct the mistake in future printings of the book, and if you are the first person to report it, I will gladly add your name to the book's acknowledgments. If you have other suggestions for improvement, I welcome those,
I continue to collect guidelines for effective programming in C++. If you have ideas for new guidelines, I'd be delighted if you'd share them with me. Send your guidelines, your comments, your criticisms, and your bug reports to:
Alternatively, you may send electronic mail to mec++@awl.com.
I maintain a list of changes to this book since its first printing, including bug-fixes, clarifications, and technical updates. This list, along with other book-related information, is available from the ftp.awl.comcp/mec++. If you would like a copy of the list of changes to this book, but you lack access to the Internet, please send a request to one of the addresses above, and I will see that the list is sent to
Enough preliminaries. On with the
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 1: Distinguish between pointers and references.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 2: Prefer C++-style casts.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 3: Never treat arrays polymorphically.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 4: Avoid gratuitous default constructors.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 5: Be wary of user-defined conversion functions.
C++ allows compilers to perform implicit conversions between types. In honor of its C heritage, for example, the language allows silent conversions from char to int and from short to double. This is why you can pass a short to a function that expects a double and still have the call succeed. The more frightening conversions in C — those that may lose information — are also present in C++, including conversion of int to short and double to (of all things) char.
You can't do anything about such conversions, because they're hard-coded into the language. When you add your own types, however, you have more control, because you can choose whether to provide the functions compilers are allowed to use for implicit type
Two kinds of functions allow compilers to perform such conversions: single-argument constructors and implicit type conversion operators. A single-argument constructor is a constructor that may be called with only one argument. Such a constructor may declare a single parameter or it may declare multiple parameters, with each parameter after the first having a default value. Here are two examples:
class Name { // for names of things
public:
Name(const string& s); // converts string to
// Name
...
};
class Rational { // for rational numbers
public:
Rational(int numerator = 0, // converts int to
int denominator = 1); // Rational
...
};
An implicit type conversion operator is simply a member function with a strange-looking name: the word operator followed by a type specification. You aren't allowed to specify a type for the function's return value, because the type of the return value is basically just the name of the function. For example, to allow Rational objects to be implicitly converted to doubles (which might be useful for mixed-mode arithmetic involving Rational objects), you might define class Rational like
class Rational {
public:
...
operator double() const; // converts Rational to
}; // double
This function would be automatically invoked in contexts like
Rational r(1, 2); // r has the value 1/2
double d = 0.5 * r; // converts r to a double,
// then does multiplication
Perhaps all this is review. That's fine, because what I really want to explain is why you usually don't want to provide type conversion functions of any
The fundamental problem is that such functions often end up being called when you neither want nor expect them to be. The result can be incorrect and unintuitive program behavior that is maddeningly difficult to
Let us deal first with implicit type conversion operators, as they are the easiest case to handle. Suppose you have a class for rational numbers similar to the one above, and you'd like to print Rational objects as if they were a built-in type. That is, you'd like to be able to do
Rational r(1, 2); cout << r; // should print "1/2"
Further suppose you forgot to write an operator<< for Rational objects. You would probably expect that the attempt to print r would fail, because there is no appropriate operator<< to call. You would be mistaken. Your compilers, faced with a call to a function called operator<< that takes a Rational, would find that no such function existed, but they would then try to find an acceptable sequence of implicit type conversions they could apply to make the call succeed. The rules defining which sequences of conversions are acceptable are complicated, but in this case your compilers would discover they could make the call succeed by implicitly converting r to a double by calling Rational::operator double. The result of the code above would be to print r as a floating point number, not as a rational number. This is hardly a disaster, but it demonstrates the disadvantage of implicit type conversion operators: their presence can lead to the wrong function being called (i.e., one other than the one
The solution is to replace the operators with equivalent functions that don't have the syntactically magic names. For example, to allow conversion of a Rational object to a double, replace operator double with a function called something like asDouble:
class Rational {
public:
...
double asDouble() const; // converts Rational
}; // to double
Such a member function must be called explicitly:
Rational r(1, 2);
cout << r; // error! No operator<<
// for Rationals
cout << r.asDouble(); // fine, prints r as a
// double
In most cases, the inconvenience of having to call conversion functions explicitly is more than compensated for by the fact that unintended functions can no longer be silently invoked. In general, the more experience C++ programmers have, the more likely they are to eschew type conversion operators. The members of string type they added to the library contains no implicit conversion from a string object to a C-style char*. Instead, there's an explicit member function, c_str, that performs that conversion. Coincidence? I think
Implicit conversions via single-argument constructors are more difficult to eliminate. Furthermore, the problems these functions cause are in many cases worse than those arising from implicit type conversion
As an example, consider a class template for array objects. These arrays allow clients to specify upper and lower index
template<class T>
class Array {
public:
Array(int lowBound, int highBound);
Array(int size);
T& operator[](int index);
...
};
The first constructor in the class allows clients to specify a range of array indices, for example, from 10 to 20. As a two-argument constructor, this function is ineligible for use as a type-conversion function. The second constructor, which allows clients to define Array objects by specifying only the number of elements in the array (in a manner similar to that used with built-in arrays), is different. It can be used as a type conversion function, and that can lead to endless
For example, consider a template specialization for comparing Array<int> objects and some code that uses such
bool operator==( const Array<int>& lhs,
const Array<int>& rhs);
Array<int> a(10);
Array<int> b(10);
...
for (int i = 0; i < 10; ++i)
if (a == b[i]) { // oops! "a" should be "a[i]"
do something for when
a[i] and b[i] are equal;
}
else {
do something for when they're not;
}
We intended to compare each element of a to the corresponding element in b, but we accidentally omitted the subscripting syntax when we typed a. Certainly we expect this to elicit all manner of unpleasant commentary from our compilers, but they will complain not at all. That's because they see a call to operator== with arguments of type Array<int> (for a) and int (for b[i]), and though there is no operator== function taking those types, our compilers notice they can convert the int into an Array<int> object by calling the Array<int> constructor that takes a single int as an argument. This they proceed to do, thus generating code for a program we never meant to write, one that looks like
for (int i = 0; i < 10; ++i) if (a == static_cast< Array<int> >(b[i])) ...
Each iteration through the loop thus compares the contents of a with the contents of a temporary array of size b[i] (whose contents are presumably undefined). Not only is this unlikely to behave in a satisfactory manner, it is also tremendously inefficient, because each time through the loop we both create and destroy a temporary Array<int> object (see Item 19).
The drawbacks to implicit type conversion operators can be avoided by simply failing to declare the operators, but single-argument constructors cannot be so easily waved away. After all, you may really want to offer single-argument constructors to your clients. At the same time, you may wish to prevent compilers from calling such constructors indiscriminately. Fortunately, there is a way to have it all. In fact, there are two ways: the easy way and the way you'll have to use if your compilers don't yet support the easy
The easy way is to avail yourself of one of the newest C++ features, the explicit keyword. This feature was introduced specifically to address the problem of implicit type conversion, and its use is about as straightforward as can be. Constructors can be declared explicit, and if they are, compilers are prohibited from invoking them for purposes of implicit type conversion. Explicit conversions are still legal,
template<class T>
class Array {
public:
...
explicit Array(int size); // note use of "explicit"
...
};
Array<int> a(10); // okay, explicit ctors can
// be used as usual for
// object construction
Array<int> b(10); // also okay
if (a == b[i]) ... // error! no way to
// implicitly convert
// int to Array<int>
if (a == Array<int>(b[i])) ... // okay, the conversion
// from int to Array<int> is
// explicit (but the logic of
// the code is suspect)
if (a == static_cast< Array<int> >(b[i])) ...
// equally okay, equally
// suspect
if (a == (Array<int>)b[i]) ... // C-style casts are also
// okay, but the logic of
// the code is still suspect
In the example using static_cast (see Item 2), the space separating the two ">" characters is no accident. If the statement were written like
if (a == static_cast<Array<int>>(b[i])) ...
it would have a different meaning. That's because C++ compilers parse ">>" as a single token. Without a space between the ">" characters, the statement would generate a syntax
If your compilers don't yet support explicit, you'll have to fall back on home-grown methods for preventing the use of single-argument constructors as implicit type conversion functions. Such methods are obvious only after you've seen
I mentioned earlier that there are complicated rules governing which sequences of implicit type conversions are legitimate and which are not. One of those rules is that no sequence of conversions is allowed to contain more than one user-defined conversion (i.e., a call to a single-argument constructor or an implicit type conversion operator). By constructing your classes properly, you can take advantage of this rule so that the object constructions you want to allow are legal, but the implicit conversions you don't want to allow are
Consider the Array template again. You need a way to allow an integer specifying the size of the array to be used as a constructor argument, but you must at the same time prevent the implicit conversion of an integer into a temporary Array object. You accomplish this by first creating a new class, ArraySize. Objects of this type have only one purpose: they represent the size of an array that's about to be created. You then modify Array's single-argument constructor to take an ArraySize object instead of an int. The code looks like
template<class T>
class Array {
public:
class ArraySize { // this class is new
public:
ArraySize(int numElements): theSize(numElements) {}
int size() const { return theSize; }
private:
int theSize;
};
Array(int lowBound, int highBound);
Array(ArraySize size); // note new declaration
...
};
Here you've nested ArraySize inside Array to emphasize the fact that it's always used in conjunction with that class. You've also made ArraySize public in Array so that anybody can use it.
Consider what happens when an Array object is defined via the class's single-argument
Array<int> a(10);
Your compilers are asked to call a constructor in the Array<int> class that takes an int, but there is no such constructor. Compilers realize they can convert the int argument into a temporary ArraySize object, and that ArraySize object is just what the Array<int> constructor needs, so compilers perform the conversion with their usual gusto. This allows the function call (and the attendant object construction) to
The fact that you can still construct Array objects with an int argument is reassuring, but it does you little good unless the type conversions you want to avoid are prevented. They are. Consider this code
bool operator==( const Array<int>& lhs,
const Array<int>& rhs);
Array<int> a(10); Array<int> b(10);
...
for (int i = 0; i < 10; ++i)
if (a == b[i]) ... // oops! "a" should be "a[i]";
// this is now an error
Compilers need an object of type Array<int> on the right-hand side of the "==" in order to call operator== for Array<int> objects, but there is no single-argument constructor taking an int argument. Furthermore, compilers cannot consider converting the int into a temporary ArraySize object and then creating the necessary Array<int> object from this temporary, because that would call for two user-defined conversions, one from int to ArraySize and one from ArraySize to Array<int>. Such a conversion sequence is verboten, so compilers must issue an error for the code attempting to perform the
The use of the ArraySize class in this example might look like a special-purpose hack, but it's actually a specific instance of a more general technique. Classes like ArraySize are often called proxy classes, because each object of such a class stands for (is a proxy for) some other object. An ArraySize object is really just a stand-in for the integer used to specify the size of the Array being created. Proxy objects can give you control over aspects of your software's behavior — in this case implicit type conversions — that is otherwise beyond your grasp, so it's well worth your while to learn how to use them. How, you might wonder, can you acquire such learning? One way is to turn to Item 30; it's devoted to proxy
Before you turn to proxy classes, however, reflect a bit on the lessons of this Item. Granting compilers license to perform implicit type conversions usually leads to more harm than good, so don't provide conversion functions unless you're sure you want
&&, ||, or ,.Item 6: Distinguish between prefix and postfix forms of increment and decrement operators.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
new and deleteItem 7: Never overload &&, ||, or ,.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 8: Understand the different meanings of new
and delete.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 9: Use destructors to prevent resource leaks.
Say good-bye to pointers. Admit it: you never really liked them that much
Okay, you don't have to say good-bye to all pointers, but you do need to say sayonara to pointers that are used to manipulate local resources. Suppose, for example, you're writing software at the Shelter for Adorable Little Animals, an organization that finds homes for puppies and kittens. Each day the shelter creates a file containing information on the adoptions it arranged that day, and your job is to write a program to read these files and do the appropriate processing for each
A reasonable approach to this task is to define an abstract base class, ALA ("Adorable Little Animal"), plus concrete derived classes for puppies and kittens. A virtual function, processAdoption, handles the necessary species-specific
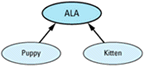
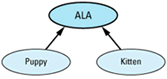
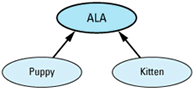
class ALA {
public:
virtual void processAdoption() = 0;
...
};
class Puppy: public ALA {
public:
virtual void processAdoption();
...
};
class Kitten: public ALA {
public:
virtual void processAdoption();
...
};
You'll need a function that can read information from a file and produce either a Puppy object or a Kitten object, depending on the information in the file. This is a perfect job for a virtual constructor, a kind of function described in Item 25. For our purposes here, the function's declaration is all we
// read animal information from s, then return a pointer // to a newly allocated object of the appropriate type ALA * readALA(istream& s);
The heart of your program is likely to be a function that looks something like
void processAdoptions(istream& dataSource)
{
while (dataSource) { // while there's data
ALA *pa = readALA(dataSource); // get next animal
pa->processAdoption(); // process adoption
delete pa; // delete object that
} // readALA returned
}
This function loops through the information in dataSource, processing each entry as it goes. The only mildly tricky thing is the need to remember to delete pa at the end of each iteration. This is necessary because readALA creates a new heap object each time it's called. Without the call to delete, the loop would contain a resource
Now consider what would happen if pa->processAdoption threw an exception. processAdoptions fails to catch exceptions, so the exception would propagate to processAdoptions's caller. In doing so, all statements in processAdoptions after the call to pa->processAdoption would be skipped, and that means pa would never be deleted. As a result, anytime pa->processAdoption throws an exception, processAdoptions contains a resource
Plugging the leak is easy
void processAdoptions(istream& dataSource)
{
while (dataSource) {
ALA *pa = readALA(dataSource);
try {
pa->processAdoption();
}
catch (...) { // catch all exceptions
delete pa; // avoid resource leak when an
// exception is thrown
throw; // propagate exception to caller
}
delete pa; // avoid resource leak when no } // exception is thrown }
but then you have to litter your code with try and catch blocks. More importantly, you are forced to duplicate cleanup code that is common to both normal and exceptional paths of control. In this case, the call to delete must be duplicated. Like all replicated code, this is annoying to write and difficult to maintain, but it also feels wrong. Regardless of whether we leave processAdoptions by a normal return or by throwing an exception, we need to delete pa, so why should we have to say that in more than one
We don't have to if we can somehow move the cleanup code that must always be executed into the destructor for an object local to processAdoptions. That's because local objects are always destroyed when leaving a function, regardless of how that function is exited. (The only exception to this rule is when you call longjmp, and this shortcoming of longjmp is the primary reason why C++ has support for exceptions in the first place.) Our real concern, then, is moving the delete from processAdoptions into a destructor for an object local to processAdoptions.
The solution is to replace the pointer pa with an object that acts like a pointer. That way, when the pointer-like object is (automatically) destroyed, we can have its destructor call delete. Objects that act like pointers, but do more, are called smart pointers, and, as Item 28 explains, you can make pointer-like objects very smart indeed. In this case, we don't need a particularly brainy pointer, we just need a pointer-like object that knows enough to delete what it points to when the pointer-like object goes out of
It's not difficult to write a class for such objects, but we don't need to. The standard C++ library (see Item E49) contains a class template called auto_ptr that does just what we want. Each auto_ptr class takes a pointer to a heap object in its constructor and deletes that object in its destructor. Boiled down to these essential functions, auto_ptr looks like
template<class T>
class auto_ptr {
public:
auto_ptr(T *p = 0): ptr(p) {} // save ptr to object
~auto_ptr() { delete ptr; } // delete ptr to object
private: T *ptr; // raw ptr to object };
The standard version of auto_ptr is much fancier, and this stripped-down implementation isn't suitable for real use3 (we must add at least the copy constructor, assignment operator, and pointer-emulating functions discussed in Item 28), but the concept behind it should be clear: use auto_ptr objects instead of raw pointers, and you won't have to worry about heap objects not being deleted, not even when exceptions are thrown. (Because the auto_ptr destructor uses the single-object form of delete, auto_ptr is not suitable for use with pointers to arrays of objects. If you'd like an auto_ptr-like template for arrays, you'll have to write your own. In such cases, however, it's often a better design decision to use a vector instead of an array,
Using an auto_ptr object instead of a raw pointer, processAdoptions looks like this:
void processAdoptions(istream& dataSource)
{
while (dataSource) {
auto_ptr<ALA> pa(readALA(dataSource));
pa->processAdoption();
}
}
This version of processAdoptions differs from the original in only two ways. First, pa is declared to be an auto_ptr<ALA> object, not a raw ALA* pointer. Second, there is no delete statement at the end of the loop. That's it. Everything else is identical, because, except for destruction, auto_ptr objects act just like normal pointers. Easy,
The idea behind auto_ptr — using an object to store a resource that needs to be automatically released and relying on that object's destructor to release it — applies to more than just pointer-based resources. Consider a function in a GUI application that needs to create a window to display some information:
// this function may leak resources if an exception
// is thrown
void displayInfo(const Information& info)
{
WINDOW_HANDLE w(createWindow());
display info in window corresponding to w;
destroyWindow(w);
}
Many window systems have C-like interfaces that use functions like createWindow and destroyWindow to acquire and release window resources. If an exception is thrown during the process of displaying info in w, the window for which w is a handle will be lost just as surely as any other dynamically allocated
The solution is the same as it was before. Create a class whose constructor and destructor acquire and release the resource:
// class for acquiring and releasing a window handle
class WindowHandle {
public:
WindowHandle(WINDOW_HANDLE handle): w(handle) {}
~WindowHandle() { destroyWindow(w); }
operator WINDOW_HANDLE() { return w; } // see below
private: WINDOW_HANDLE w;
// The following functions are declared private to prevent // multiple copies of a WINDOW_HANDLE from being created. // See Item 28 for a discussion of a more flexible approach. WindowHandle(const WindowHandle&); WindowHandle& operator=(const WindowHandle&); };
This looks just like the auto_ptr template, except that assignment and copying are explicitly prohibited (see Item E27), and there is an implicit conversion operator that can be used to turn a WindowHandle into a WINDOW_HANDLE. This capability is essential to the practical application of a WindowHandle object, because it means you can use a WindowHandle just about anywhere you would normally use a raw WINDOW_HANDLE. (See Item 5, however, for why you should generally be leery of implicit type conversion
Given the WindowHandle class, we can rewrite displayInfo as
// this function avoids leaking resources if an
// exception is thrown
void displayInfo(const Information& info)
{
WindowHandle w(createWindow());
display info in window corresponding to w;
}
Even if an exception is thrown within displayInfo, the window created by createWindow will always be
By adhering to the rule that resources should be encapsulated inside objects, you can usually avoid resource leaks in the presence of exceptions. But what happens if an exception is thrown while you're in the process of acquiring a resource, e.g., while you're in the constructor of a resource-acquiring class? What happens if an exception is thrown during the automatic destruction of such resources? Don't constructors and destructors call for special techniques? They do, and you can read about them in Items 10 and 11.
Item 10: Prevent resource leaks in constructors.
Imagine you're developing software for a multimedia address book. Such an address book might hold, in addition to the usual textual information of a person's name, address, and phone numbers, a picture of the person and the sound of their voice (possibly giving the proper pronunciation of their
To implement the book, you might come up with a design like
class Image { // for image data
public:
Image(const string& imageDataFileName);
...
};
class AudioClip { // for audio data
public:
AudioClip(const string& audioDataFileName);
...
};
class PhoneNumber { ... }; // for holding phone numbers
class BookEntry { // for each entry in the
public: // address book
BookEntry(const string& name,
const string& address = "",
const string& imageFileName = "",
const string& audioClipFileName = "");
~BookEntry();
// phone numbers are added via this function
void addPhoneNumber(const PhoneNumber& number);
...
private:
string theName; // person's name
string theAddress; // their address
list<PhoneNumber> thePhones; // their phone numbers
Image *theImage; // their image
AudioClip *theAudioClip; // an audio clip from them
};
Each BookEntry must have name data, so you require that as a constructor argument (see Item 3), but the other fields — the person's address and the names of files containing image and audio data — are optional. Note the use of the list class to hold the person's phone numbers. This is one of several container classes that are part of the standard C++ library (see Item E49 and Item 35).
A straightforward way to write the BookEntry constructor and destructor is as
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
Const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(0), theAudioClip(0)
{
if (imageFileName != "") {
theImage = new Image(imageFileName);
}
if (audioClipFileName != "") {
theAudioClip = new AudioClip(audioClipFileName);
}
}
BookEntry::~BookEntry()
{
delete theImage;
delete theAudioClip;
}
The constructor initializes the pointers theImage and theAudioClip to null, then makes them point to real objects if the corresponding arguments are non-empty strings. The destructor deletes both pointers, thus ensuring that a BookEntry object doesn't give rise to a resource leak. Because C++ guarantees it's safe to delete null pointers, BookEntry's destructor need not check to see if the pointers actually point to something before deleting
Everything looks fine here, and under normal conditions everything is fine, but under abnormal conditions — under exceptional conditions — things are not fine at
Consider what will happen if an exception is thrown during execution of this part of the BookEntry
if (audioClipFileName != "") {
theAudioClip = new AudioClip(audioClipFileName);
}
An exception might arise because operator new (see Item 8) is unable to allocate enough memory for an AudioClip object. One might also arise because the AudioClip constructor itself throws an exception. Regardless of the cause of the exception, if one is thrown within the BookEntry constructor, it will be propagated to the site where the BookEntry object is being
Now, if an exception is thrown during creation of the object theAudioClip is supposed to point to (thus transferring control out of the BookEntry constructor), who deletes the object that theImage already points to? The obvious answer is that BookEntry's destructor does, but the obvious answer is wrong. BookEntry's destructor will never be called.
C++ destroys only fully constructed objects, and an object isn't fully constructed until its constructor has run to completion. So if a BookEntry object b is created as a local
void testBookEntryClass()
{
BookEntry b("Addison-Wesley Publishing Company",
"One Jacob Way, Reading, MA 01867");
...
}
and an exception is thrown during construction of b, b's destructor will not be called. Furthermore, if you try to take matters into your own hands by allocating b on the heap and then calling delete if an exception is
void testBookEntryClass()
{
BookEntry *pb = 0;
try {
pb = new BookEntry("Addison-Wesley Publishing Company",
"One Jacob Way, Reading, MA 01867");
...
}
catch (...) { // catch all exceptions
delete pb; // delete pb when an
// exception is thrown
throw; // propagate exception to
} // caller
delete pb; // delete pb normally
}
you'll find that the Image object allocated inside BookEntry's constructor is still lost, because no assignment is made to pb unless the new operation succeeds. If BookEntry's constructor throws an exception, pb will be the null pointer, so deleting it in the catch block does nothing except make you feel better about yourself. Using the smart pointer class auto_ptr<BookEntry> (see Item 9) instead of a raw BookEntry* won't do you any good either, because the assignment to pb still won't be made unless the new operation
There is a reason why C++ refuses to call destructors for objects that haven't been fully constructed, and it's not simply to make your life more difficult. It's because it would, in many cases, be a nonsensical thing — possibly a harmful thing — to do. If a destructor were invoked on an object that wasn't fully constructed, how would the destructor know what to do? The only way it could know would be if bits had been added to each object indicating how much of the constructor had been executed. Then the destructor could check the bits and (maybe) figure out what actions to take. Such bookkeeping would slow down constructors, and it would make each object larger, too. C++ avoids this overhead, but the price you pay is that partially constructed objects aren't automatically destroyed. (For an example of a similar trade-off involving efficiency and program behavior, turn to Item E13.)
Because C++ won't clean up after objects that throw exceptions during construction, you must design your constructors so that they clean up after themselves. Often, this involves simply catching all possible exceptions, executing some cleanup code, then rethrowing the exception so it continues to propagate. This strategy can be incorporated into the BookEntry constructor like
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(0), theAudioClip(0)
{
try { // this try block is new
if (imageFileName != "") {
theImage = new Image(imageFileName);
}
if (audioClipFileName != "") {
theAudioClip = new AudioClip(audioClipFileName);
}
}
catch (...) { // catch any exception
delete theImage; // perform necessary
delete theAudioClip; // cleanup actions
throw; // propagate the exception
}
}
There is no need to worry about BookEntry's non-pointer data members. Data members are automatically initialized before a class's constructor is called, so if a BookEntry constructor body begins executing, the object's theName, theAddress, and thePhones data members have already been fully constructed. As fully constructed objects, these data members will be automatically destroyed when the BookEntry object containing them is, and there is no need for you to intervene. Of course, if these objects' constructors call functions that might throw exceptions, those constructors have to worry about catching the exceptions and performing any necessary cleanup before allowing them to
You may have noticed that the statements in BookEntry's catch block are almost the same as those in BookEntry's destructor. Code duplication here is no more tolerable than it is anywhere else, so the best way to structure things is to move the common code into a private helper function and have both the constructor and the destructor call
class BookEntry {
public:
... // as before
private:
...
void cleanup(); // common cleanup statements
};
void BookEntry::cleanup()
{
delete theImage;
delete theAudioClip;
}
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(0), theAudioClip(0)
{
try {
... // as before
}
catch (...) {
cleanup(); // release resources
throw; // propagate exception
}
}
BookEntry::~BookEntry()
{
cleanup();
}
This is nice, but it doesn't put the topic to rest. Let us suppose we design our BookEntry class slightly differently so that theImage and theAudioClip are constant
class BookEntry {
public:
... // as above
private:
...
Image * const theImage; // pointers are now
AudioClip * const theAudioClip; // const
};
Such pointers must be initialized via the member initialization lists of BookEntry's constructors, because there is no other way to give const pointers a value (see Item E12). A common temptation is to initialize theImage and theAudioClip like
// an implementation that may leak resources if an
// exception is thrown
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(imageFileName != ""
? new Image(imageFileName)
: 0),
theAudioClip(audioClipFileName != ""
? new AudioClip(audioClipFileName)
: 0)
{}
but this leads to the problem we originally wanted to eliminate: if an exception is thrown during initialization of theAudioClip, the object pointed to by theImage is never destroyed. Furthermore, we can't solve the problem by adding try and catch blocks to the constructor, because try and catch are statements, and member initialization lists allow only expressions. (That's why we had to use the ?: syntax instead of the if-then-else syntax in the initialization of theImage and theAudioClip.)
Nevertheless, the only way to perform cleanup chores before exceptions propagate out of a constructor is to catch those exceptions, so if we can't put try and catch in a member initialization list, we'll have to put them somewhere else. One possibility is inside private member functions that return pointers with which theImage and theAudioClip should be
class BookEntry {
public:
... // as above
private:
... // data members as above
Image * initImage(const string& imageFileName);
AudioClip * initAudioClip(const string&
audioClipFileName);
};
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(initImage(imageFileName)),
theAudioClip(initAudioClip(audioClipFileName))
{}
// theImage is initialized first, so there is no need to
// worry about a resource leak if this initialization
// fails. This function therefore handles no exceptions
Image * BookEntry::initImage(const string& imageFileName)
{
if (imageFileName != "") return new Image(imageFileName);
else return 0;
}
// theAudioClip is initialized second, so it must make
// sure theImage's resources are released if an exception
// is thrown during initialization of theAudioClip. That's
// why this function uses try...catch.
AudioClip * BookEntry::initAudioClip(const string&
audioClipFileName)
{
try {
if (audioClipFileName != "") {
return new AudioClip(audioClipFileName);
}
else return 0;
}
catch (...) {
delete theImage;
throw;
}
}
This is perfectly kosher, and it even solves the problem we've been laboring to overcome. The drawback is that code that conceptually belongs in a constructor is now dispersed across several functions, and that's a maintenance
A better solution is to adopt the advice of Item 9 and treat the objects pointed to by theImage and theAudioClip as resources to be managed by local objects. This solution takes advantage of the facts that both theImage and theAudioClip are pointers to dynamically allocated objects and that those objects should be deleted when the pointers themselves go away. This is precisely the set of conditions for which the auto_ptr classes (see Item 9) were designed. We can therefore change the raw pointer types of theImage and theAudioClip to their auto_ptr
class BookEntry {
public:
... // as above
private:
...
const auto_ptr<Image> theImage; // these are now
const auto_ptr<AudioClip> theAudioClip; // auto_ptr objects
};
Doing this makes BookEntry's constructor leak-safe in the presence of exceptions, and it lets us initialize theImage and theAudioClip using the member initialization
BookEntry::BookEntry(const string& name,
const string& address,
const string& imageFileName,
const string& audioClipFileName)
: theName(name), theAddress(address),
theImage(imageFileName != ""
? new Image(imageFileName)
: 0),
theAudioClip(audioClipFileName != ""
? new AudioClip(audioClipFileName)
: 0)
{}
In this design, if an exception is thrown during initialization of theAudioClip, theImage is already a fully constructed object, so it will automatically be destroyed, just like theName, theAddress, and thePhones. Furthermore, because theImage and theAudioClip are now objects, they'll be destroyed automatically when the BookEntry object containing them is. Hence there's no need to manually delete what they point to. That simplifies BookEntry's destructor
BookEntry::~BookEntry()
{} // nothing to do!
This means you could eliminate BookEntry's destructor
It all adds up to this: if you replace pointer class members with their corresponding auto_ptr objects, you fortify your constructors against resource leaks in the presence of exceptions, you eliminate the need to manually deallocate resources in destructors, and you allow const member pointers to be handled in the same graceful fashion as non-const
Dealing with the possibility of exceptions during construction can be tricky, but auto_ptr (and auto_ptr-like classes) can eliminate most of the drudgery. Their use leaves behind code that's not only easy to understand, it's robust in the face of exceptions,
Item 11: Prevent exceptions from leaving destructors.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 12: Understand how throwing an exception differs from passing a parameter or calling a virtual function.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 13: Catch exceptions by reference.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 14: Use exception specifications judiciously.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 15: Understand the costs of exception handling.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 16: Remember the 80-20 rule.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 17: Consider using lazy evaluation.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 18: Amortize the cost of expected computations.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 19: Understand the origin of temporary objects.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 20: Facilitate the return value optimization.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 21: Overload to avoid implicit type conversions.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 22: Consider using op= instead of stand-alone op.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 23: Consider alternative libraries.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 24: Understand the costs of virtual functions, multiple inheritance, virtual base classes, and RTTI.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 25: Virtualizing constructors and non-member functions.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 26: Limiting the number of objects of a class.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 27: Requiring or prohibiting heap-based objects.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 31: Making functions virtual with respect to more than one object.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 32: Program in the future tense.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
Item 33: Make non-leaf classes abstract.
Suppose you're working on a project whose software deals with animals. Within this software, most animals can be treated pretty much the same, but two kinds of animals — lizards and chickens — require special handling. That being the case, the obvious way to relate the classes for animals, lizards, and chickens is like
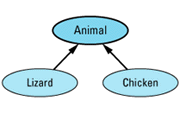
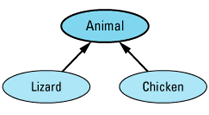
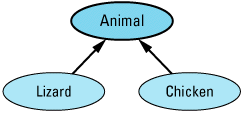
The Animal class embodies the features shared by all the creatures you deal with, and the Lizard and Chicken classes specialize Animal in ways appropriate for lizards and chickens,
Here's a sketch of the definitions for these
class Animal {
public:
Animal& operator=(const Animal& rhs);
...
};
class Lizard: public Animal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public Animal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
Only the assignment operators are shown here, but that's more than enough to keep us busy for a while. Consider this
Lizard liz1; Lizard liz2;
Animal *pAnimal1 = &liz1; Animal *pAnimal2 = &liz2;
...
*pAnimal1 = *pAnimal2;
There are two problems here. First, the assignment operator invoked on the last line is that of the Animal class, even though the objects involved are of type Lizard. As a result, only the Animal part of liz1 will be modified. This is a partial assignment. After the assignment, liz1's Animal members have the values they got from liz2, but liz1's Lizard members remain
The second problem is that real programmers write code like this. It's not uncommon to make assignments to objects through pointers, especially for experienced C programmers who have moved to C++. That being the case, we'd like to make the assignment behave in a more reasonable fashion. As Item 32 points out, our classes should be easy to use correctly and difficult to use incorrectly, and the classes in the hierarchy above are easy to use
One approach to the problem is to make the assignment operators virtual. If Animal::operator= were virtual, the assignment would invoke the Lizard assignment operator, which is certainly the correct one to call. However, look what happens if we declare the assignment operators
class Animal {
public:
virtual Animal& operator=(const Animal& rhs);
...
};
class Lizard: public Animal {
public:
virtual Lizard& operator=(const Animal& rhs);
...
};
class Chicken: public Animal {
public:
virtual Chicken& operator=(const Animal& rhs);
...
};
Due to relatively recent changes to the language, we can customize the return value of the assignment operators so that each returns a reference to the correct class, but the rules of C++ force us to declare identical parameter types for a virtual function in every class in which it is declared. That means the assignment operator for the Lizard and Chicken classes must be prepared to accept any kind of Animal object on the right-hand side of an assignment. That, in turn, means we have to confront the fact that code like the following is
Lizard liz;
Chicken chick;
Animal *pAnimal1 = &liz;
Animal *pAnimal2 = &chick;
...
*pAnimal1 = *pAnimal2; // assign a chicken to
// a lizard!
This is a mixed-type assignment: a Lizard is on the left and a Chicken is on the right. Mixed-type assignments aren't usually a problem in C++, because the language's strong typing generally renders them illegal. By making Animal's assignment operator virtual, however, we opened the door to such mixed-type
This puts us in a difficult position. We'd like to allow same-type assignments through pointers, but we'd like to forbid mixed-type assignments through those same pointers. In other words, we want to allow
Animal *pAnimal1 = &liz1; Animal *pAnimal2 = &liz2; ... *pAnimal1 = *pAnimal2; // assign a lizard to a lizardbut we want to prohibit this:
Animal *pAnimal1 = &liz; Animal *pAnimal2 = &chick; ... *pAnimal1 = *pAnimal2; // assign a chicken to a lizard
Distinctions such as these can be made only at runtime, because sometimes assigning *pAnimal2 to *pAnimal1 is valid, sometimes it's not. We thus enter the murky world of type-based runtime errors. In particular, we need to signal an error inside operator= if we're faced with a mixed-type assignment, but if the types are the same, we want to perform the assignment in the usual
We can use a dynamic_cast (see Item 2) to implement this behavior. Here's how to do it for Lizard's assignment
Lizard& Lizard::operator=(const Animal& rhs)
{
// make sure rhs is really a lizard
const Lizard& rhs_liz = dynamic_cast<const Lizard&>(rhs);
proceed with a normal assignment of rhs_liz to *this;
}
This function assigns rhs to *this only if rhs is really a Lizard. If it's not, the function propagates the bad_cast exception that dynamic_cast throws when the cast fails. (Actually, the type of the exception is std::bad_cast, because the components of the standard library, including the exceptions thrown by the standard components, are in the namespace std. For an overview of the standard library, see Item E49 and Item 35.)
Even without worrying about exceptions, this function seems needlessly complicated and expensive — the dynamic_cast must consult a type_info structure; see Item 24 — in the common case where one Lizard object is assigned to
Lizard liz1, liz2;
...
liz1 = liz2; // no need to perform a
// dynamic_cast: this
// assignment must be valid
We can handle this case without paying for the complexity or cost of a dynamic_cast by adding to Lizard the conventional assignment
class Lizard: public Animal {
public:
virtual Lizard& operator=(const Animal& rhs);
Lizard& operator=(const Lizard& rhs); // add this
...
};
Lizard liz1, liz2;
...
liz1 = liz2; // calls operator= taking
// a const Lizard&
Animal *pAnimal1 = &liz1;
Animal *pAnimal2 = &liz2;
...
*pAnimal1 = *pAnimal2; // calls operator= taking
// a const Animal&
In fact, given this latter operator=, it's simplicity itself to implement the former one in terms of
Lizard& Lizard::operator=(const Animal& rhs)
{
return operator=(dynamic_cast<const Lizard&>(rhs));
}
This function attempts to cast rhs to be a Lizard. If the cast succeeds, the normal class assignment operator is called. Otherwise, a bad_cast exception is
Frankly, all this business of checking types at runtime and using dynamic_casts makes me nervous. For one thing, some compilers still lack support for dynamic_cast, so code that uses it, though theoretically portable, is not necessarily portable in practice. More importantly, it requires that clients of Lizard and Chicken be prepared to catch bad_cast exceptions and do something sensible with them each time they perform an assignment. In my experience, there just aren't that many programmers who are willing to program that way. If they don't, it's not clear we've gained a whole lot over our original situation where we were trying to guard against partial
Given this rather unsatisfactory state of affairs regarding virtual assignment operators, it makes sense to regroup and try to find a way to prevent clients from making problematic assignments in the first place. If such assignments are rejected during compilation, we don't have to worry about them doing the wrong
The easiest way to prevent such assignments is to make operator= private in Animal. That way, lizards can be assigned to lizards and chickens can be assigned to chickens, but partial and mixed-type assignments are
class Animal {
private:
Animal& operator=(const Animal& rhs); // this is now
... // private
};
class Lizard: public Animal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public Animal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
Lizard liz1, liz2;
...
liz1 = liz2; // fine
Chicken chick1, chick2;
...
chick1 = chick2; // also fine
Animal *pAnimal1 = &liz1;
Animal *pAnimal2 = &chick1;
...
*pAnimal1 = *pAnimal2; // error! attempt to call
// private Animal::operator=
Unfortunately, Animal is a concrete class, and this approach also makes assignments between Animal objects
Animal animal1, animal2;
...
animal1 = animal2; // error! attempt to call
// private Animal::operator=
Moreover, it makes it impossible to implement the Lizard and Chicken assignment operators correctly, because assignment operators in derived classes are responsible for calling assignment operators in their base classes (see Item E16):
Lizard& Lizard::operator=(const Lizard& rhs)
{
if (this == &rhs) return *this;
Animal::operator=(rhs); // error! attempt to call
// private function. But
// Lizard::operator= must
// call this function to
... // assign the Animal parts
} // of *this!
We can solve this latter problem by declaring Animal::operator= protected, but the conundrum of allowing assignments between Animal objects while preventing partial assignments of Lizard and Chicken objects through Animal pointers remains. What's a poor programmer to
The easiest thing is to eliminate the need to allow assignments between Animal objects, and the easiest way to do that is to make Animal an abstract class. As an abstract class, Animal can't be instantiated, so there will be no need to allow assignments between Animals. Of course, this leads to a new problem, because our original design for this system presupposed that Animal objects were necessary. There is an easy way around this difficulty. Instead of making Animal itself abstract, we create a new class — AbstractAnimal, say — consisting of the common features of Animal, Lizard, and Chicken objects, and we make that class abstract. Then we have each of our concrete classes inherit from AbstractAnimal. The revised hierarchy looks like
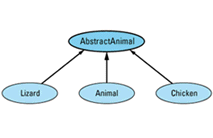
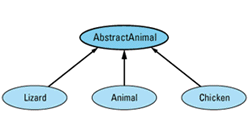

and the class definitions are as
class AbstractAnimal {
protected:
AbstractAnimal& operator=(const AbstractAnimal& rhs);
public:
virtual ~AbstractAnimal() = 0; // see below
...
};
class Animal: public AbstractAnimal {
public:
Animal& operator=(const Animal& rhs);
...
};
class Lizard: public AbstractAnimal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public AbstractAnimal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
This design gives you everything you need. Homogeneous assignments are allowed for lizards, chickens, and animals; partial assignments and heterogeneous assignments are prohibited; and derived class assignment operators may call the assignment operator in the base class. Furthermore, none of the code written in terms of the Animal, Lizard, or Chicken classes requires modification, because these classes continue to exist and to behave as they did before AbstractAnimal was introduced. Sure, such code has to be recompiled, but that's a small price to pay for the security of knowing that assignments that compile will behave intuitively and assignments that would behave unintuitively won't
For all this to work, AbstractAnimal must be abstract — it must contain at least one pure virtual function. In most cases, coming up with a suitable function is not a problem, but on rare occasions you may find yourself facing the need to create a class like AbstractAnimal in which none of the member functions would naturally be declared pure virtual. In such cases, the conventional technique is to make the destructor a pure virtual function; that's what's shown above. In order to support polymorphism through pointers correctly, base classes need virtual destructors anyway (see Item E14), so the only cost associated with making such destructors pure virtual is the inconvenience of having to implement them outside their class definitions. (For an example, see page 195.)
(If the notion of implementing a pure virtual function strikes you as odd, you just haven't been getting out enough. Declaring a function pure virtual doesn't mean it has no implementation, it
=0").
True, most pure virtual functions are never implemented, but pure virtual destructors are a special case. They must be implemented, because they are called whenever a derived class destructor is invoked. Furthermore, they often perform useful tasks, such as releasing resources (see Item 9) or logging messages. Implementing pure virtual functions may be uncommon in general, but for pure virtual destructors, it's not just common, it's mandatory.)
You may have noticed that this discussion of assignment through base class pointers is based on the assumption that concrete base classes like Animal contain data members. If there are no data members, you might point out, there is no problem, and it would be safe to have a concrete class inherit from a second, dataless, concrete
One of two situations applies to your data-free would-be concrete base class: either it might have data members in the future or it might not. If it might have data members in the future, all you're doing is postponing the problem until the data members are added, in which case you're merely trading short-term convenience for long-term grief (see also Item 32). Alternatively, if the base class should truly never have any data members, that sounds very much like it should be an abstract class in the first place. What use is a concrete base class without
Replacement of a concrete base class like Animal with an abstract base class like AbstractAnimal yields benefits far beyond simply making the behavior of operator= easier to understand. It also reduces the chances that you'll try to treat arrays polymorphically, the unpleasant consequences of which are examined in Item 3. The most significant benefit of the technique, however, occurs at the design level, because replacing concrete base classes with abstract base classes forces you to explicitly recognize the existence of useful abstractions. That is, it makes you create new abstract classes for useful concepts, even if you aren't aware of the fact that the useful concepts
If you have two concrete classes C1 and C2 and you'd like C2 to publicly inherit from C1, you should transform that two-class hierarchy into a three-class hierarchy by creating a new abstract class A and having both C1 and C2 publicly inherit from
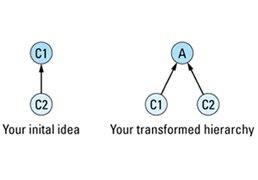
The primary value of this transformation is that it forces you to identify the abstract class A. Clearly, C1 and C2 have something in common; that's why they're related by public inheritance (see Item E35). With this transformation, you must identify what that something is. Furthermore, you must formalize the something as a class in C++, at which point it becomes more than just a vague something, it achieves the status of a formal abstraction, one with well-defined member functions and well-defined
All of which leads to some worrisome thinking. After all, every class represents some kind of abstraction, so shouldn't we create two classes for every concept in our hierarchy, one being abstract (to embody the abstract part of the abstraction) and one being concrete (to embody the object-generation part of the abstraction)? No. If you do, you'll end up with a hierarchy with too many classes. Such a hierarchy is difficult to understand, hard to maintain, and expensive to compile. That is not the goal of object-oriented
The goal is to identify useful abstractions and to force them — and only them — into existence as abstract classes. But how do you identify useful abstractions? Who knows what abstractions might prove useful in the future? Who can predict who's going to want to inherit from
Well, I don't know how to predict the future uses of an inheritance hierarchy, but I do know one thing: the need for an abstraction in one context may be coincidental, but the need for an abstraction in more than one context is usually meaningful. Useful abstractions, then, are those that are needed in more than one context. That is, they correspond to classes that are useful in their own right (i.e., it is useful to have objects of that type) and that are also useful for purposes of one or more derived
This is precisely why the transformation from concrete base class to abstract base class is useful: it forces the introduction of a new abstract class only when an existing concrete class is about to be used as a base class, i.e., when the class is about to be (re)used in a new context. Such abstractions are useful, because they have, through demonstrated need, shown themselves to be
The first time a concept is needed, we can't justify the creation of both an abstract class (for the concept) and a concrete class (for the objects corresponding to that concept), but the second time that concept is needed, we can justify the creation of both the abstract and the concrete classes. The transformation I've described simply mechanizes this process, and in so doing it forces designers and programmers to represent explicitly those abstractions that are useful, even if the designers and programmers are not consciously aware of the useful concepts. It also happens to make it a lot easier to bring sanity to the behavior of assignment
Let's consider a brief example. Suppose you're working on an application that deals with moving information between computers on a network by breaking it into packets and transmitting them according to some protocol. All we'll consider here is the class or classes for representing packets. We'll assume such classes make sense for this
Suppose you deal with only a single kind of transfer protocol and only a single kind of packet. Perhaps you've heard that other protocols and packet types exist, but you've never supported them, nor do you have any plans to support them in the future. Should you make an abstract class for packets (for the concept that a packet represents) as well as a concrete class for the packets you'll actually be using? If you do, you could hope to add new packet types later without changing the base class for packets. That would save you from having to recompile packet-using applications if you add new packet types. But that design requires two classes, and right now you need only one (for the particular type of packets you use). Is it worth complicating your design now to allow for future extension that may never take
There is no unequivocally correct choice to be made here, but experience has shown it is nearly impossible to design good classes for concepts we do not understand well. If you create an abstract class for packets, how likely are you to get it right, especially since your experience is limited to only a single packet type? Remember that you gain the benefit of an abstract class for packets only if you can design that class so that future classes can inherit from it without its being changed in any way. (If it needs to be changed, you have to recompile all packet clients, and you've gained
It is unlikely you could design a satisfactory abstract packet class unless you were well versed in many different kinds of packets and in the varied contexts in which they are used. Given your limited experience in this case, my advice would be not to define an abstract class for packets, adding one later only if you find a need to inherit from the concrete packet
The transformation I've described here is a way to identify the need for abstract classes, not the way. There are many other ways to identify good candidates for abstract classes; books on object-oriented analysis are filled with them. It's not the case that the only time you should introduce abstract classes is when you find yourself wanting to have a concrete class inherit from another concrete class. However, the desire to relate two concrete classes by public inheritance is usually indicative of a need for a new abstract
As is often the case in such matters, brash reality sometimes intrudes on the peaceful ruminations of theory. Third-party C++ class libraries are proliferating with gusto, and what are you to do if you find yourself wanting to create a concrete class that inherits from a concrete class in a library to which you have only read
You can't modify the library to insert a new abstract class, so your choices are both limited and
class Window { // this is the library class
public:
virtual void resize(int newWidth, int newHeight);
virtual void repaint() const;
int width() const;
int height() const;
};
class SpecialWindow { // this is the class you
public: // wanted to have inherit
... // from Window
// pass-through implementations of nonvirtual functions
int width() const { return w.width(); }
int height() const { return w.height(); }
// new implementations of "inherited" virtual functions
virtual void resize(int newWidth, int newHeight);
virtual void repaint() const;
private:
Window w;
};
None of these choices is particularly attractive, so you have to apply some engineering judgment and choose the poison you find least unappealing. It's not much fun, but life's like that sometimes. To make things easier for yourself (and the rest of us) in the future, complain to the vendors of libraries whose designs you find wanting. With luck (and a lot of comments from clients), those designs will improve as time goes
Still, the general rule remains: non-leaf classes should be abstract. You may need to bend the rule when working with outside libraries, but in code over which you have control, adherence to it will yield dividends in the form of increased reliability, robustness, comprehensibility, and extensibility throughout your
Item 34: Understand how to combine C++ and C in the same program.
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
[This item is not part of the Effective C++ CD demo. To see which Items are available, click here.]
So your appetite for information on C++ remains unsated. Fear not, there's more — much more. In the sections that follow, I put forth my recommendations for further reading on C++. It goes without saying that such recommendations are both subjective and selective, but in view of the litigious age in which we live, it's probably a good idea to say it
There are hundreds — possibly thousands — of books on C++, and new contenders join the fray with great frequency. I haven't seen all these books, much less read them, but my experience has been that while some books are very good, some of them, well, some of them
What follows is the list of books I find myself consulting when I have questions about software development in C++. Other good books are available, I'm sure, but these are the ones I use, the ones I can truly recommend.
A good place to begin is with the books that describe the language itself. Unless you are crucially dependent on the nuances of the
These books contain not just a description of what's in the language, they also explain the rationale behind the design decisions — something you won't find in the official standard documents. The Annotated C++ Reference Manual is now incomplete (several language features have been added since it was published — see Item 35) and is in some cases out of date, but it is still the best reference for the core parts of the language, including templates and exceptions. The Design and Evolution of C++ covers most of what's missing in The Annotated C++ Reference Manual; the only thing it lacks is a discussion of the Standard Template Library (again, see Item 35). These books are not tutorials, they're references, but you can't truly understand C++ unless you understand the material in these
For a more general reference on the language, the standard library, and how to apply it, there is no better place to look than the book by the man responsible for C++ in the first
Stroustrup has been intimately involved in the language's design, implementation, application, and standardization since its inception, and he probably knows more about it than anybody else does. His descriptions of language features make for dense reading, but that's primarily because they contain so much information. The chapters on the standard C++ library provide a good introduction to this crucial aspect of modern
If you're ready to move beyond the language itself and are interested in how to apply it effectively, you might consider my other book on the
That book is organized similarly to this one, but it covers different (arguably more fundamental)
A book pitched at roughly the same level as my Effective C++ books, but covering different topics,
Murray's book is especially strong on the fundamentals of template design, a topic to which he devotes two chapters. He also includes a chapter on the important topic of migrating from C development to C++ development. Much of my discussion on reference counting (see Item 29) is based on the ideas in C++ Strategies and Tactics.
If you're the kind of person who likes to learn proper programming technique by reading code, the book for you
Each chapter in this book starts with some C++ software that has been published as an example of how to do something correctly. Cargill then proceeds to dissect — nay, vivisect — each program, identifying likely trouble spots, poor design choices, brittle implementation decisions, and things that are just plain wrong. He then iteratively rewrites each example to eliminate the weaknesses, and by the time he's done, he's produced code that is more robust, more maintainable, more efficient, and more portable, and it still fulfills the original problem specification. Anybody programming in C++ would do well to heed the lessons of this book, but it is especially important for those involved in code
(One topic Cargill does not discuss in C++ Programming Style is exceptions. He turns his critical eye to this language feature in the following article, however, which demonstrates why writing exception-safe code is more difficult than most programmers
If you are contemplating the use of exceptions, read this article before you
Once you've mastered the basics of C++ and are ready to start pushing the envelope, you must familiarize yourself
I generally refer to this as "the LSD book," because it's purple and it will expand your mind. Coplien covers some straightforward material, but his focus is really on showing you how to do things in C++ you're not supposed to be able to do. You want to construct objects on top of one another? He shows you how. You want to bypass strong typing? He gives you a way. You want to add data and functions to classes as your programs are running? He explains how to do it. Most of the time, you'll want to steer clear of the techniques he describes, but sometimes they provide just the solution you need for a tricky problem you're facing. Furthermore, it's illuminating just to see what kinds of things can be done with C++. This book may frighten you, it may dazzle you, but when you've read it, you'll never look at C++ the same way
If you have anything to do with the design and implementation of C++ libraries, you would be foolhardy to
Carroll and Ellis discuss many practical aspects of library design and implementation that are simply ignored by everybody else. Good libraries are small, fast, extensible, easily upgraded, graceful during template instantiation, powerful, and robust. It is not possible to optimize for each of these attributes, so one must make trade-offs that improve some aspects of a library at the expense of others. Designing and Coding Reusable C++ examines these trade-offs and offers down-to-earth advice on how to go about making
Regardless of whether you write software for scientific and engineering applications, you owe yourself a look
The first part of the book explains C++ for FORTRAN programmers (now there's an unenviable task), but the latter parts cover techniques that are relevant in virtually any domain. The extensive material on templates is close to revolutionary; it's probably the most advanced that's currently available, and I suspect that when you've seen the miracles these authors perform with templates, you'll never again think of them as little more than souped-up
Finally, the emerging discipline of patterns in object-oriented software development (see page 123) is described
This book provides an overview of the ideas behind patterns, but its primary contribution is a catalogue of 23 fundamental patterns that are useful in many application areas. A stroll through these pages will almost surely reveal a pattern you've had to invent yourself at one time or another, and when you find one, you're almost certain to discover that the design in the book is superior to the ad-hoc approach you came up with. The names of the patterns here have already become part of an emerging vocabulary for object-oriented design; failure to know these names may soon be hazardous to your ability to communicate with your colleagues. A particular strength of the book is its emphasis on designing and implementing software so that future evolution is gracefully accommodated (see Items 32 and 33).
Design Patterns is also available as a
For hard-core C++ programmers, there's really only one game in
The magazine has made a conscious decision to move away from its "C++ only" roots, but the increased coverage of domain- and system-specific programming issues is worthwhile in its own right, and the material on C++, if occasionally a bit off the deep end, continues to be the best
If you're more comfortable with C than with C++, or if you find the C++ Report's material too extreme to be useful, you may find the articles in this magazine more to your
As the name suggests, this covers both C and C++. The articles on C++ tend to assume a weaker background than those in the C++ Report. In addition, the editorial staff keeps a tighter rein on its authors than does the Report, so the material in the magazine tends to be relatively mainstream. This helps filter out ideas on the lunatic fringe, but it also limits your exposure to techniques that are truly
Three Usenet newsgroups are devoted to C++. The general-purpose anything-goes newsgroup is comp.lang.c++
. The postings there run the gamut from detailed explanations of advanced programming techniques to rants and raves by those who love or hate C++ to undergraduates the world over asking for help with the homework assignments they neglected until too late. Volume in the newsgroup is extremely high. Unless you have hours of free time on your hands, you'll want to employ a filter to help separate the wheat from the chaff. Get a good filter — there's a lot of
In November 1995, a moderated version of comp.lang.c++ was created. Named comp.lang.c++.moderated, this newsgroup is also designed for general discussion of C++ and related issues, but the moderators aim to weed out implementation-specific questions and comments, questions covered in the extensive
A more narrowly focused newsgroup is comp.std.c++, which is devoted to a discussion of
Items 9, 10, 26, 31 and 32 attest to the remarkable utility of the auto_ptr template. Unfortunately, few compilers currently ship with a "correct" implementation.1 Items 9 and 28 sketch how you might write one yourself, but it's nice to have more than a sketch when embarking on real-world
Below are two presentations of an implementation for auto_ptr. The first presentation documents the class interface and implements all the member functions outside the class definition. The second implements each member function within the class definition. Stylistically, the second presentation is inferior to the first, because it fails to separate the class interface from its implementation. However, auto_ptr yields simple classes, and the second presentation brings that out much more clearly than does the
Here is auto_ptr with its interface
template<class T>
class auto_ptr {
public:
explicit auto_ptr(T *p = 0); // see Item 5 for a
// description of "explicit"
template<class U> // copy constructor member auto_ptr(auto_ptr<U>& rhs); // template (see Item 28): // initialize a new auto_ptr // with any compatible // auto_ptr
~auto_ptr();
template<class U> // assignment operator auto_ptr<T>& // member template (see operator=(auto_ptr<U>& rhs); // Item 28): assign from any // compatible auto_ptr
T& operator*() const; // see Item 28 T* operator->() const; // see Item 28
T* get() const; // return value of current
// dumb pointer
T* release(); // relinquish ownership of
// current dumb pointer and
// return its value
void reset(T *p = 0); // delete owned pointer;
// assume ownership of p
private:
T *pointee;
template<class U> // make all auto_ptr classes friend class auto_ptr<U>; // friends of one another };
template<class T>
inline auto_ptr<T>::auto_ptr(T *p)
: pointee(p)
{}
template<class T>
inline auto_ptr<T>::auto_ptr(auto_ptr<U>& rhs)
: pointee(rhs.release())
{}
template<class T>
inline auto_ptr<T>::~auto_ptr()
{ delete pointee; }
template<class T>
template<class U>
inline auto_ptr<T>& auto_ptr<T>::operator=(auto_ptr<U>& rhs)
{
if (this != &rhs) reset(rhs.release());
return *this;
}
template<class T>
inline T& auto_ptr<T>::operator*() const
{ return *pointee; }
template<class T>
inline T* auto_ptr<T>::operator->() const
{ return pointee; }
template<class T>
inline T* auto_ptr<T>::get() const
{ return pointee; }
template<class T> inline T* auto_ptr<T>::release() { T *oldPointee = pointee; pointee = 0; return oldPointee; }
template<class T>
inline void auto_ptr<T>::reset(T *p)
{
if (pointee != p) {
delete pointee;
pointee = p;
}
}
Here is auto_ptr with all the functions defined in the class definition. As you can see, there's no brain surgery going on
template<class T>
class auto_ptr {
public:
explicit auto_ptr(T *p = 0): pointee(p) {}
template<class U>
auto_ptr(auto_ptr<U>& rhs): pointee(rhs.release()) {}
~auto_ptr() { delete pointee; }
template<class U>
auto_ptr<T>& operator=(auto_ptr<U>& rhs)
{
if (this != &rhs) reset(rhs.release());
return *this;
}
T& operator*() const { return *pointee; }
T* operator->() const { return pointee; }
T* get() const { return pointee; }
T* release()
{
T *oldPointee = pointee;
pointee = 0;
return oldPointee;
}
void reset(T *p = 0)
{
if (pointee != p) {
delete pointee;
pointee = p;
}
}
private:
T *pointee;
template<class U> friend class auto_ptr<U>;
};
If your compilers don't yet support explicit, you may safely #define it out of
#define explicit
This won't make auto_ptr any less functional, but it will render it slightly less safe. For details, see Item 5.
If your compilers lack support for member templates, you can use the non-template auto_ptr copy constructor and assignment operator described in Item 28. This will make your auto_ptrs less convenient to use, but there is, alas, no way to approximate the behavior of member templates. If member templates (or other language features, for that matter) are important to you, let your compiler vendors know. The more customers ask for new language features, the sooner vendors will implement
auto_ptr
as for years been a moving target. The final specification was adopted only in
November 1997. For details, consult auto_ptr information at this book's WWW Site.
Note that the auto_ptr described here omits a few details present in the official version, such as the fact that auto_ptr is in the std namespace (see Item 35) and that its member functions promise not to throw exceptions.dynamic_cast is to find the beginning of the memory occupied by an object. We explore that capability in Item 27.
auto_ptr appears on pages 291-294.
uncaught_exception, that returns true if an exception is active and has not yet been caught.
typedef." I don't know why. If you need a portable solution, you must — it hurts me to write this — make CallBackPtr a macro, sigh.
->" operator, so it->second should now work. Some STL implementations fail to satisfy this requirement, however, so (*it).second is still the more portable construct.
operator* above may now yield the same (optimized) object code.
8
At least that's what's supposed to happen. Alas, some compilers treat T(lhs) as a cast to remove lhs's constness, then add rhs to lhs and return a reference to the modified lhs! Test your compilers before relying on the behavior described above.
Return
9 In July 1996, the
Return
string type in the standard C++ library (see Item E49 and Item 35) uses a combination of solutions two and three. The reference returned from the non-const operator[] is guaranteed to be valid until the next function call that might modify the string. After that, use of the reference (or the character to which it refers) yields undefined results. This allows the string's shareability flag to be reset to true whenever a function is called that might modify the string.
type_info::name, and different implementations behave differently. (Given a class SpaceShip, for example, one implementation's type_info::name returns "class SpaceShip".) A better design would identify a class by the address of its associated type_info object, because that is guaranteed to be unique. HitMap would then be declared to be of type map<const type_info*, HitFunctionPtr>.