Win32 System Programming
Win32 System Programming
|
Win32 System Programming
|
|
GO TO [Program][Graphs][Observations][Thread Serialization][SMP Operation][Single Resource][Improving Performance][Semaphores][Interpretation][Experiments][Performance Tab Settings][Priority in Critical Code][Sleeping in Critical Code][Negative Impact][Alignment] Thread Performance, Critical Sections, and MutexesWith Performance Test Program, Performance Graphs, and Analysis Please feel free to send me additional information at jmhart@world.std.com. I greatly appreciate the assistance of David Poulton (DP), Christian Vogler (CV) and Vadim Kavalerov (VK) who have contributed extensively with ideas, data and encouragement. IntroductionExercise 11-2 (Page 251) addresses the relative performance of critical sections (CSs) and mutexes. Very simple experiments (the kind I had in mind for the exercise) show that critical sections are decisively faster than mutexes. The reason is that, when you execute EnterCriticalSection and the CS is not owned, the thread never enters the kernel. There is a simple interlocked atomic test in user space, and the thread continues if the CS is not owned by some other thread. If the CS is already owned by a different thread, then the thread enters the kernel and blocks on a mutex or some other kernel synchronization object. A WaitForSingleObject call on a mutex, however, must enter the kernel, even to detect that the mutex is not owned. This behavior was observed consistently, first with only a single thread, and then several, contending for the CS or mutex. However, several readers and course participants also reported degraded performance, and increased kernel time, when there were "too many" threads contending for a single critical section, but this behavior was not observed when contending for a mutex. "Two many" seems to be five or more, as the data below will show, and the performance degradation can be dramatic. I'll show a simple technique (thread serialization) that will allow you to have numerous threads contending for a single CS without this serious performance degradation. One reader, David Poulton, then pointed out that the behavior can also change dramatically when the test program runs in the background rather than the foreground, and he provided a test program to demonstrate this effect. In particular, the kernel time increased significantly, so the behavior could not be explained entirely by thread and process priority. The number of threads that are ready to run, or "active," also plays a role. The experiments will show that this behavior can be at least partially explained by the fact that the foreground thread is an additional thread, and, in addition, the other threads will have decreased priority due to the fact that their process is in the background. Bottom Line:
I modified David's test program to test several factors which could effect overall performance. These factors are controlled through command line parameters:
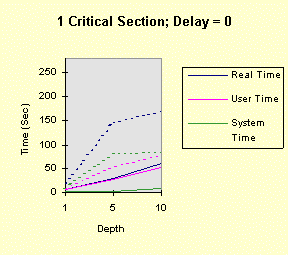
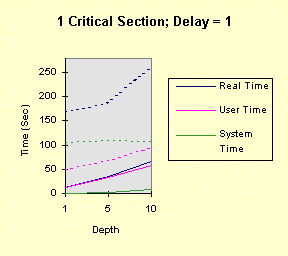
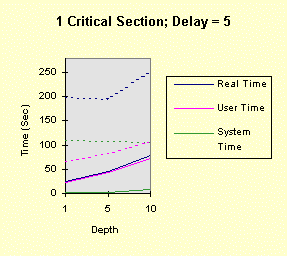
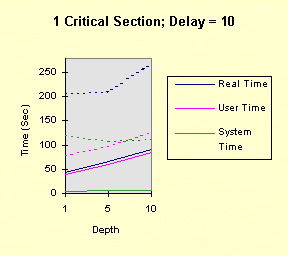
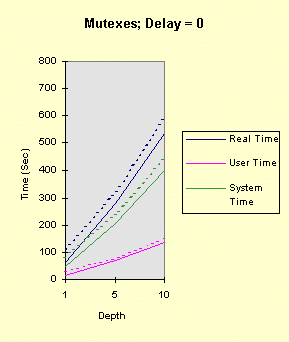
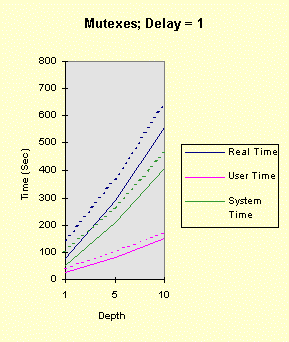
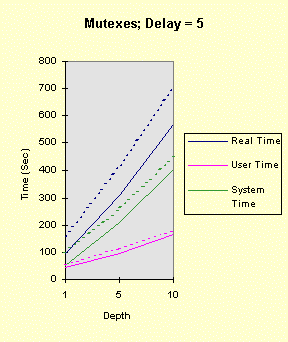
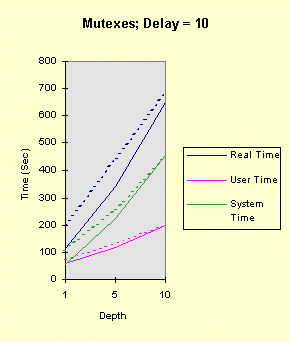
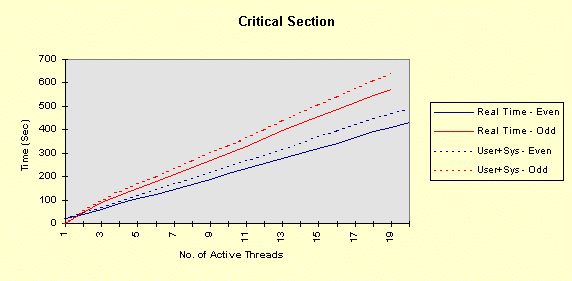
The program below achieves all of this, with command line arguments allowing you to vary the factors above. The program comments explain everything. Performance graphs are at the end of the program show the impact of several of the factors, both in the foreground and the background, followed by analysis and interpretation. Christian Vogler (CV) contributed heavily to this section. /********************************************************************/ /* Program to test the various Win32 synchronization techniques for the mutual exclusion problem. Critical Sections and mutexes are compared, in terms of performance, in a very simple fashion. Nearly all the factors that can impact threaded performance are represented here in a simplified way so that you can study the plausibility of various designs. Number of threads Use of mutexes or critical sections Nested resource acquisition CPU and I/O intensity Control of the number of active threads (thread synchronization) Usage: TimeMutex Which [Depth [Delay [NumThreads [SleepPoints [NumThActive]]]]] Which: 1 - Test Critical Sections 2 - Test nested Critical Sections 3 - Test Mutexes CONCEPT: We will determine the relative performance characteristics of CSs and mutexes, especially the amount of time they spend in the kernel. Testing two distinct nested CSs will determine if there is a linear (doubling) or nonlinear performance impact. Depth: 1 (default) for the number of enter calls followed by the same number of leave calls Can be 0 to show effect of no synchronization calls CONCEPT: is the performance impact linear with depth? Delay: 0 (default) or more for a delay factor to waste CPU time after all nested enters and before the nested leaves. That is, the thread performs CPU-intensive tasks while holding the "resources." CONCEPT: A large delay is indicative of CPU-intensive threads. A CPU-Intensive thread may have its priority increased but it might also be preempted for another thread. NumThreads: Number of concurrent threads contending for the CRITICAL_SECTION or mutex. Must be between 1 and 64 (the max for WaitForMultipleObjects). 4 is the default value. CONCEPT: Determine if total elapsed time is linear with the number of threads. A large number of threads contending for the same resources might degrade performance non-linearly. SleepPoints: 0 [Default] Never sleep, hence do not yield CPU 1 Sleep(0) after obtaining all resources, yielding the CPU while holding the resources 2 Sleep(0) after releasing all resources, yielding the CPU without holding any resources 3 Sleep(0) at both points CONCEPT: Yielding the CPU shows the best-case effect on a thread that performs I/O or blocks for other reasons. NumThActive: Number of activated threads. NumThreads is the default. All other threads are waiting on a semaphore. CONCEPT: Performance may improve if we limit the number of concurrently active threads contending for the same resources. This also has the effect of serializing thread execution, esp. with low values. ADDITIONAL TESTING CONCEPT: Determine if performance varies depending upon operation in the foreground or background. Author: Johnson (John) M. Hart. April 23, 1998. Extended May 10, 1998 Please send me additional information at jmhart@world.std.com. This code is provided as supplementary material to "Win32 System Programming" by Johnson M. Hart, Addison Wesley Longman, 1997. http://cseng.aw.com/bookdetail.qry?ISBN=0-201-63465-1&ptype=0 Based on an idea from David Poulton, with reuse of a small amount of code. Build as a MULTITHREADED CONSOLE APPLICATION. */ /********************************************************************/ #include <stdio.h> #include <windows.h> #include <stdlib.h> #include <process.h> #define ITERATIONS 1000000 /* Number of times to iterate through the mutual exclusion test */ #define THREADS 4 /* Default Number of threads contending for the same "resource". Cannot be more than 64 (limitation of WaitForMultipleObjects) */ DWORD WINAPI CrSecProc(LPVOID); DWORD WINAPI CrSecProcA(LPVOID); DWORD WINAPI MutexProc(LPVOID); int DelayFactor = 0, Which = 1, Depth = 1, NumThreads = THREADS, SleepPoints = 0; int NumThActive; HANDLE hMutex; /* Mutex handle */ HANDLE hSem; /* Semaphore limiting active threads */ CRITICAL_SECTION hCritical, hCriticalA; /* Critical Section objects */ /********************************************************************/ /* Time wasting function. Waste a random amount of CPU time. */ /********************************************************************/ void WasteTime (DWORD DelayFactor) { int Delay, k, i; if (DelayFactor == 0) return; Delay = (DWORD)(DelayFactor * (float)rand()/RAND_MAX); for (i = 0; i < Delay; i++) k = rand()*rand(); /* Waste time */ return; } /************************************************************************/ /* For each mutual exclusion algorithm create the threads and wait for */ /* them to finish */ /************************************************************************/ int main(int argc, char * argv[]) { HANDLE *hThreadHandles; /* Array to hold the thread handles */ DWORD ThreadID; /* Dummy variable to hold the thread identifier. */ int iTh; /* Loop Control Variables */ FILETIME FileTime; /* Times to seed random #s. */ SYSTEMTIME SysTi; /* TimeMutex Which [Depth [Delay [NumThreads [SleepPoints]]]] */ /* Randomly initialize the random number seed */ GetSystemTime (&SysTi); SystemTimeToFileTime (&SysTi, &FileTime); srand (FileTime.dwLowDateTime); if (argc >= 2) Which = atoi (argv[1]); if (argc >= 3) Depth = atoi (argv[2]); if (argc >= 4) DelayFactor = atoi (argv[3]); if (argc >= 5) NumThreads = atoi (argv[4]); if (argc >= 6) SleepPoints = atoi (argv[5]); if (argc >= 7) NumThActive = max (atoi (argv[6]), 1); else NumThActive = NumThreads; if (Which != 1 && Which != 2 && Which != 3) { printf ("The first command line argument must be 1, 2, or 3\n"); return 1; } if (!(NumThreads >= 1 && NumThreads <= MAXIMUM_WAIT_OBJECTS)) { printf ("Number of threads must be between 1 and %d\n", MAXIMUM_WAIT_OBJECTS); return 2; } NumThActive = min (NumThActive, NumThreads); if (!(SleepPoints >= 0 && SleepPoints <= 3)) SleepPoints = 0; printf ("Which = %d, Depth = %d, Delay = %d, NumThreads = %d,\ SleepPoints = %d, NumThActive = %d\n", Which, Depth, DelayFactor, NumThreads, SleepPoints, NumThActive); if (Which == 3) hMutex = CreateMutex (NULL, FALSE, NULL); if (Which == 1 || Which == 2) InitializeCriticalSection (&hCritical); if (Which == 2) InitializeCriticalSection (&hCriticalA); hSem = CreateSemaphore (NULL, NumThActive, NumThActive, NULL); if (hSem == NULL) { printf ("Cannot create gating semaphore. %d\n", GetLastError()); return 3; } /* Create all the threads, then wait for them to complete */ hThreadHandles = malloc (NumThreads * sizeof(HANDLE)); if (hThreadHandles == NULL) { printf ("Cannot allocate memory for thread handles.\n"); return 4; } for(iTh = 0; iTh < NumThreads; iTh++) { if((hThreadHandles[iTh] = (HANDLE)_beginthreadex (NULL, 0, Which == 1 ? CrSecProc : Which == 3 ? MutexProc : CrSecProcA, NULL, 0, &ThreadID)) == NULL) { printf("Error Creating Thread %d\n", iTh); return 1; } } WaitForMultipleObjects(NumThreads, hThreadHandles, TRUE,INFINITE); for(iTh=0; iTh<NumThreads; iTh++) CloseHandle(hThreadHandles[iTh]); free (hThreadHandles); if (Which == 1 || Which == 2) DeleteCriticalSection(&hCritical); if (Which == 2) DeleteCriticalSection(&hCriticalA); if (Which == 3) CloseHandle(hMutex); } /********************************************************************/ /* Simple thread functions to enter and leave CS or mutex Each thread must wait on the gating semaphore before starting and releases the semaphore upon completion */ /********************************************************************/ DWORD WINAPI MutexProc(LPVOID Nothing) { int i, k; WaitForSingleObject (hSem, INFINITE); /* Serialization semaphore */ for (i = 0; i < ITERATIONS; i++) { for (k = 0; k < Depth; k++) /* Depth may be 0 */ if(WaitForSingleObject(hMutex, INFINITE) == WAIT_FAILED) { printf("Wait for Mutex failed: %d\n", GetLastError()); break; } if (SleepPoints % 2 == 1) Sleep (0); /* Yield the CPU, holding the resources */ WasteTime (DelayFactor); /* Critical Section code to go here */ for (k = 0; k < Depth; k++) ReleaseMutex(hMutex); if (SleepPoints >= 2) Sleep (0); /* Yield the CPU, not holding the resources */ } ReleaseSemaphore (hSem, 1, &i); return 0; } DWORD WINAPI CrSecProc(LPVOID Nothing) { int i, k; WaitForSingleObject (hSem, INFINITE); /* Serialization semaphore */ for (i = 0; i < ITERATIONS; i++) { for (k = 0; k < Depth; k++) EnterCriticalSection (&hCritical); if (SleepPoints % 2 == 1) Sleep (0); /* Yield the CPU, holding the resources */ WasteTime (DelayFactor); /* Critical Section code to go here */ for (k = 0; k < Depth; k++) LeaveCriticalSection(&hCritical); if (SleepPoints >= 2) Sleep (0); /* Yield the CPU, not holding the resources */ } ReleaseSemaphore (hSem, 1, &i); return 0; } DWORD WINAPI CrSecProcA(LPVOID Nothing) { /* Use a CRITICAL_SECTION pair to emulate two resources */ int i, k; WaitForSingleObject (hSem, INFINITE); /* Serialization semaphore */ for (i = 0; i < ITERATIONS; i++) { for (k = 0; k < Depth; k++) { EnterCriticalSection (&hCritical); EnterCriticalSection (&hCriticalA); } if (SleepPoints % 2 == 1) Sleep (0); /* Yield the CPU, holding the resources */ WasteTime (DelayFactor); /* Critical Section code to go here */ for (k = 0; k < Depth; k++) { LeaveCriticalSection(&hCriticalA); LeaveCriticalSection(&hCritical); } if (SleepPoints >= 2) Sleep (0); /* Yield the CPU, holding the resources */ } ReleaseSemaphore (hSem, 1, &i); return 0; } The following graphs show the performance results on a 100MHz Pentium (antique, I know, but adequate for our purposes as we are interested in relative timings) running Windows NT 4.0, SP3 on an otherwise idle system. The system has 32 MB, adequate for the demands of this simple program. In all cases, there were 4 threads (all active), one nesting level, and no sleep points. The graphs show different delay values (hence, several levels of CPU-intensity), mutexes, and critical sections (both one CS and two CSs), and foreground vs. background operation. Timing was performed using Chapter 8's timep program. "System Time" is equivalent to "Kernel Time." [Note: These charts represent only one run of the program rather than an average of several identical runs. Furthermore, there is no baseline test in which there is no synchronization at all, but you can perform such tests by setting the Depth parameter to 0. You will find that the kernel time does not increase when running in the background.] The graphs show the results when the process is running in the foreground (solid lines) and background (dashed lines). Notice that the CS programs consume large amounts of kernel time when they are in the background. The mutex version is only marginally slower in the background and can be faster than the CS version, in the background case, when the depth is low. Also notice that the total CPU utilization is nearly 100% in all cases (you can see this with the performance monitor). To place the test program in the background, simply click on another window (such as another DOS prompt); it is not necessary to create any activity in that window. The first four graphs show the results of: timep timemutex 1 depth delay 4 0 4 -- for depth = 1, 5, 10, and delay = 0, 1, 5, 10
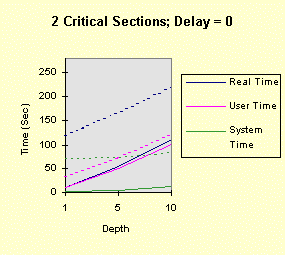
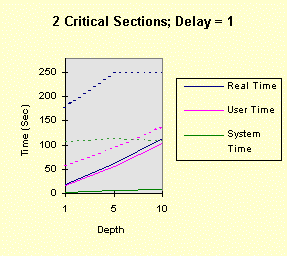
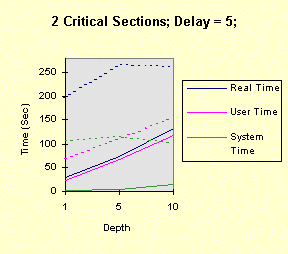
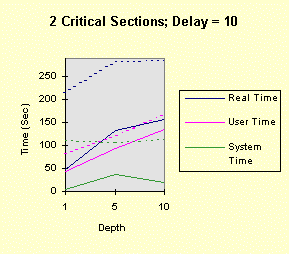
Notice that the performance depends linearly (approximately) on the depth and delay. The next four graphs show the results when there are two, rather than one, critical section. The commands, then, are: timep timemutex 2 depth delay 4 0 4 -- for depth = 1, 5, 10, and delay = 0, 1, 5, 10 The results show that all times increase due the fact that there are two, rather than one, EnterCriticalSection calls for each loop iteration. However, the second critical section does not change the qualitative nature of the results. In particular, the performance degradation occurs at exactly the same points.
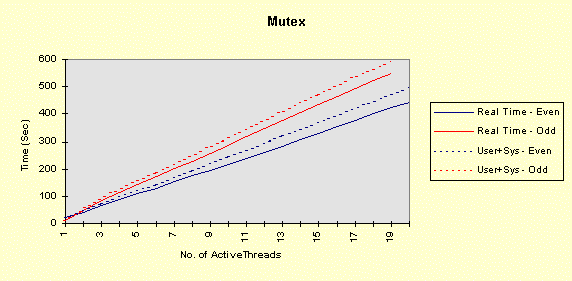
The next test sequence repeats the first, but with a mutex, rather than a CRITICAL_SECTION. That is, the commands are: timep timemutex 3 depth delay 4 0 4 -- for depth = 1, 5, 10, and delay = 0, 1, 5, 10 The mutex introduces a considerable system time overhead for each wait call. The elapsed time grows linearly with the depth, as expected. Performance degrades slightly when the process is in the background, but not as dramatically as with the critical sections. Furthermore, the degradation is a small, consistent amount that might be explained by the decreased process priority and the fact that there is at least one additional thread for the foreground process. Also notice that, for a depth of one, mutexes are preferable if the process is intended to operate as part of a background process.
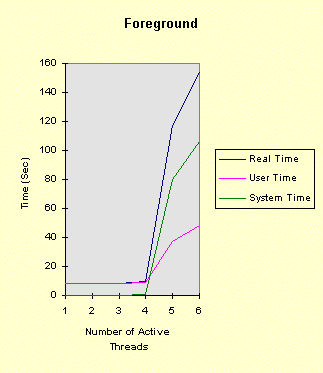
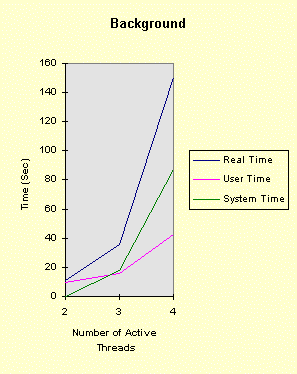
Some Other ObservationsNumber of Threads: If you increase the number of threads to 8, performance degrades dramatically, even in the foreground. Even 5 threads degrades performance non-linearly. We might expect a 20% increase in elapsed time in going from 4 threads to 5 as each thread does the same amount of work. Limiting the Number of Active Threads (Thread Serialization): This is very effective when using a CS, and the elapsed time is now approximately linear with the number of threads. Even going from 3 threads to 4 starts to show degraded performance. It appears that NT can efficiently maintain about 4 "active" threads (threads in the ready state) contending for a single CS. Note: The kernel time waiting on the semaphore is not significant as each thread only waits once. We could have a finer-grained thread control, of course. The next section shows some experimental results. This effect can be seen by running the above test sequences with the last parameter set to 2 or 3. Then, the background cases are similar to the foreground cases. Thus, the total number of threads in the kernel "ready" state seems to have an important performance impact. Note: This thread serialization plays a role similar to that played by I/O Completion Ports (Book, Page 282). The downside of thread serialization is that you do not achieve maximum concurrency, which may lead to other inefficiencies. Sleep Points while Holding Resources is Very Harmful to Performance: Try a value of 1 or 3, and you will see the effect. This is as expected as all the other threads are blocked while the sleeping thread gives up the CPU, the other threads block on the resources, and then the sleeping thread finally executes again. Sleep points without holding the resources have very little negative impact. More on Thread SerializationHere are the results for the following test sequence:
That is, there are six threads contending for a single critical section. There are no sleep points. The test is repeated for each possible value of the number of active threads. The left graph shows the foreground results, while the right graph shows the background results. The foreground results confirm the observations in the preceding section. Running the process in the background is roughly equivalent to adding one or two more active threads.
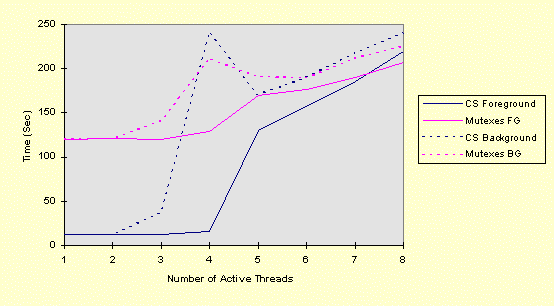
The next graph compares a CS and a mutex with a large number of active threads in order to demonstrate mutex scalability. This time there are 8 threads, and the number of active threads varies from 1 to 8. Only the elapsed times are shown. The two command sets are:
and
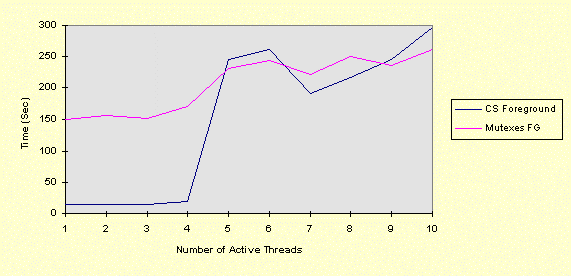
Note the odd spike at 4 threads. Here's the same test with 10 active threads.
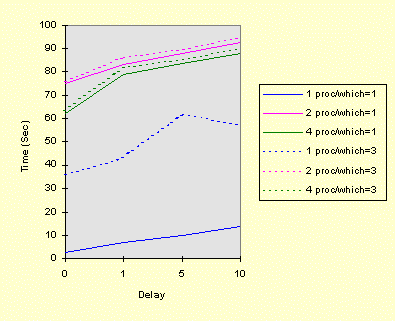
Operation on an SMP SystemThe next step is to determine the performance on SMP systems. In principle, we would expect the elapsed time to decrease as the number of processors is increased because the different threads can run concurrently on different processors. It turns out, however, that when these threads are contending for the same resource, such as a CRITICAL_SECTION, the performance can degrade. The degradation is due to the mechanisms that the hardware and the NT executive use to synchronize shared memory access between several processors. I'd like to thank David Poulton (two-processor systems) and Vadim Kavalerov (four-processor systems) for providing the test results. Both used systems with a 200MHz Pentium Pro and produced compatible results, so the results are all presented on the same graph. Note on elapsed time (DP): The SMP graphs show elapsed (real) time exclusively. An important SMP concept, which may be counterintuitive, is that this is often less than the time the threads were scheduled on any particular processor, due to the inherent parallelism in the architecture. We saw this effect with the sortMT program in Chapter 10 (see Appendix C for the timing results). Thus, the relationships are:
User and kernel times may in some cases give a better indication of the actual workload, whereas real time measures the actual performance as perceived by the user. Active Threads Contending for a Single ResourceThe first test sequence and graph show the real (or elapsed) time running in the foreground, using the parameters:
The graphs shows one (blue), two (purple), and four (green) processor results. As there were only four threads, additional processors would not provide better results. Solid lines are the times for a CRITICAL_SECTIION (Which == 1), and the dotted lines represent the mutex (Which == 3). The horizontal axis is the "Delay" parameter, and we would expect the elapsed time to increase linearly with the Delay value, and this is, very approximately, the case. There is, however, a large constant factor due to resource contention between processors.
Observe the following:
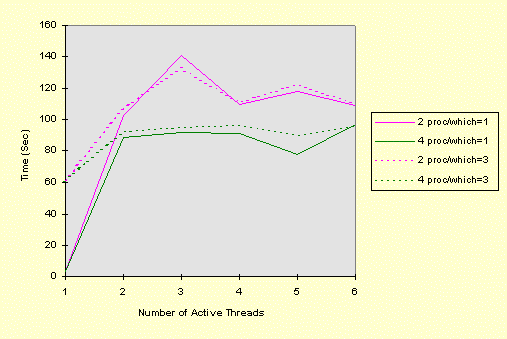
It would appear that Microsoft will want to address this issue in the future. It will be important to do so if NT is to scale well in the enterprise. Having said that, note that my test program is extreme in that the resource requests occur at a high frequency, higher than might occur in an actual application. Improving Performance by Serializing Thread ExecutionThe next test sequence ran with the parameters:
The number of active threads (the last parameter on the command line) varies from one to six. In all cases, there are six threads, so the actual amount of computation remains constant. The results are shown below for two and four processors; again, the solid lines show the CS solution (Which == 1) and the dotted lines are the mutex solution (Which == 3). The horizontal axis shows the number of active threads, which, in turn, is the maximum number of threads that can actually be running at any one time.
Here are some observations.
Serialization is a viable technique to achieve the best performance when several threads contend for the same resource. What, then, is the value of threading if they have to execute sequentially? The answer would be that the thread model can simplify programming and allows one thread to become blocked for I/O (or some other reason) while another runs. Nonetheless, when multiple threads contend for a single resource, SMP is likely to result in degraded performance. The SMP Even/Odd PhenomenonDavid Poulton supplied some more intriguing, and seemingly paradoxical, results on his two-processor system. His experiments consisted of running, first, 2n threads (all active) and then 2n-1 threads (also all active) for various values of n (1, 2, 3, …) and finding that the even number of threads (2n) completed faster than the 2n-1 case, which had one less thread. Note that the total amount of work is proportional to the number of threads. "One of the interesting SMP findings I observed was the 2n being faster than the 2n-1 problem, and in some cases I get 2n-3 and 2n-5 running slower. I got this behavior with my original program, but I can easily recreate it with timemutex. This can be done by turning the serialization off (setting NumThActive to the number of threads), or possibly serializing on an odd then even set of threads and comparing. The first graph below shows this happening with a Critical Section and the second with a mutex." The data was gathered by running:
and
The results they are a pretty compelling argument for the use of serialization on SMP. A bigger workload involving 20 threads is faster than smaller a workload involving 15!
Request to Readers: It would be very interesting to get results running on a Digital (Compaq?) Alpha system to see if SMP produces better results than the Pentium Pro. Future results with the Merced processor should also be interesting. Relevant Notes from VK: "More than 4 CPU can't be placed on a single system board, because the APIC of PPro supports only 4 processors. Therefore 4-way is maximum that Intel, AMI, and other vendors make." "There are some exotic (experimental) bigger systems but they have to use multiple system boards and a fast interconnect. These systems don't perform as well per CPU because of the problem with several CPU accessing RAM at the same time. The system memory bus supported by PPro is just not fast enough to support more processors. Also, cache coherence begins to severely impact the performance. Alpha is a different story, though." Final Notes on SMP Performance, and Thread Performance in GeneralFirst, remember that SMP systems can provide excellent performance when the threads are not contending. The sortMT and grepMT results (Chapter 10 and Appendix C) illustrate the possibilities. As another example, VK points out that Microquill (http://www.microquill.com) provides a threaded heap management library that performs very well on SMP systems, going from 93 to 2 seconds (somehow, they get more than 4:1) and beating the C library malloc/free easily. See their home page for benchmark results. Secondly, this test program is "highly contentious" with the threads spending very little time without the resource. That is, as soon as they release the resource, they go back and request it again with hardly any delay. In "real life," you may find that your threads are not so contentious. You could modify the program so that the thread wastes some time outside of the critical sections in order to model the actual behavior of your system. Nonetheless, these results do show the possible performance degradation, often counter intuitive, that can occur with SMP systems or threads contending for a single resource, even on a single processor system. Mutual Exclusion with Events and SemaphoresDavid Poulton's original program also timed mutual exclusion using, first, an event, and second, a semaphore. There was no nesting allowed, so the semaphore had a maximum value of one (it was a "binary semaphore" rather than a "counting semaphore"). The event was an autoreset event that was signaled with SetEvent, allowing exactly one thread through at a time. Note that these solutions cannot take advantage of the idea of ownership. David's results show that the semaphore and event solutions are marginally faster than the mutex solution. Presumably, this advantage is due to the fact that ownership does not need to be managed. InterpretationThe relative performance of mutexes and critical sections is explained by the fact, stated earlier, that critical sections are first tested in user space. Mutexes, and, by extension, events and semaphores, perform well even when a large number of threads are contending for them. Critical sections, on the other hand, do not perform well unless you limit the number of active threads (serialize contention). I have had trouble coming up with a consistent theory to explain the performance degradation observed with critical sections. I would have expected a similar effect as with mutexes. After rereading the appropriate chapters in Custer's Inside Windows NT, I worked out various charts to show threads going from the wait state to the ready state and getting a priority boost on the way (Custer says that this happens, and it makes sense). While I could see that the threads could get in "lock step" (each thread would perform an Enter-Leave sequence and then be preempted by another thread, blocked on the same CS). But this should happen with even two threads, so I can't see why two, three, or even four threads perform well. Furthermore, it does not explain what happens when the process is in the background, for there is no increase in the number of threads contending for the CS. I disassembled the user-space code using the VC+ 5.0 debugger and found what might be a busy wait loop for EnterCriticalSection, and there are also tests on flags other than the CS count. So, someone may want to analyze that code to see if that provides and answer. Regardless of cause, this lack of scalability when using CSs appears to be an undesirable property. Perhaps someone could comment or clarify the situation. Please send me mail with any authoritative information. Note (DP): Foreground thread boosting. Solomon's 1998 update of Custer describes the foreground/background process priority switching as "Quantum Stretching" pp 205-207. It ONLY happens in NT workstation and not NT Server. It would be interesting to see what would happen to timemutex if run on a uniprocessor NT Server configuration with a foreground process? More ExperimentsChristian Vogler performed several additional experiments. All comments below are CV's unless specified otherwise. First, the numbers for elapsed time (I did not bother to check mutexes). [JMH Note: These times appear to be compatible with my own, although the background case is even worse.]
Performance Tab SettingsNow a very interesting thing. I played with the settings in the Performance tab of Control Panel/System. Usually I have set the performance boost to a maximum for foreground applications. I changed these settings, and here are the results for foreground processing:
I had quite a load on my machine at the time of testing (VC++, ICQ, Telnet, 2 consoles, Explorer), so the numbers are probably a bit higher than they should be, and also more variable. But I repeated the tests a few times, and they were pretty consistent within +/- 10% elapsed time. [JMH Note: The elapsed time would appear to be due to the effects of the busy system.] Increasing Thread Priority within the Critical Code SectionChanging the CrSecProc() function to the following made the program take up exactly the same amount of time in the foreground and in the background. It also seems to confirm my speculations above. Unfortunately it is not a solution to the problem in its present form, because the SetThreadPriority() system call overhead makes the program slower by an order of magnitude. It now runs for 1:03 minutes on my machine, instead of 5 3/4 seconds. Here is the code. [JMH note: the code calls:
after the EnterCriticalSection loop and then, after the LeaveCriticalSection loop, there is a call to:
Sleeping within the Critical Code SectionThe next experiment was to call Sleep (0) within the WasteTime function. As a result, the thread loses the CPU and another thread gains control. [JMH Note: It would be interesting to try this on an SMP system. This is similar to a sleep point value of 1] The result is as expected. Things just take around 30 times longer. That is the time it seems to take the waiting threads to unblock from the kernel object, to re-test the critical section, and to block on the kernel object again. Actually, I expected things to take even longer than that. I noticed a strange thing when I disassembled the relevant functions, with the NT 4 kernel symbols loaded. Internally, RtlEnterCriticalSection calls RtlWaitForCriticalSection, which in turn calls ZwWaitForSingleObject. As best as I can determine (I am not very good at reading x86 assembly code), it calls it with a timeout value of 0. You Need Several Threads to Get the Negative Performance ImpactI found out two more things. The first one baffles me, and the second one is a relief, because I was beginning to fear for the worst:
Even More, Including AlignmentI was planning to do a thread trace by putting rdtsc instructions in the appropriate places so that we can find out which thread is doing what at what times. I'll have to increase the working set size and use VirtualLock() to make sure that page faults don't distort the measurements. BTW, is there a way to lock code pages into the working set as well, beside pages allocated with VirtualAlloc()? I first checked out the QueryPerformanceCounter() call, but it is too slow to get accurate results. It seems to do something similar to the rdtsc instruction, but in order to compute the result, it switches to kernel mode. I can't understand why the Windows NT designers did it that way! It takes more than 1000 clock cycles on my machine, as opposed to 12. When I first tested rdtsc, I noticed an interesting thing. The performance of a critical section also depends a lot on the memory address that the CRITICAL_SECTION structure is aligned on, at least on a P5. In order to maximize performance, you have to align the structure such that the RecursionCount field starts a new L1 cache line. This means that the CS structure should start on A-8, where A is a memory address divisible by 32. It seems that the P5 invalidates the cache line that contains CRITICAL_SECTION::LockCount when it executes the lock inc dword ptr [edx+4] instruction or other locked instructions on dword ptr [edx+4]. So, in the worst case, you get unnecessary L1 cache misses every time you attempt to enter or leave a CS. During my experiments, this slowed down the EnterCriticalSection()/LeaveCriticalSection() calls up to a factor of 2, depending on where exactly the new cache line was started. |