Return to Top Page
Sequential File Processing Timing
Appendix C (pp. 338-339) used ASCII to UNICODE file conversion as a means to compare
various sequential file processing methods. The idea is to read a file sequentially,
perform some lightweight processing, and write the results sequentially to a different
file. In this case, the output file is twice as long as the input file.
Appendix C used the atouLBSS ("large buffer,
sequential scan") version as the fastest that could be achieved easily using normal
Win32 file I/O. The FILE_FLAG_SEQUENTIAL_SCAN flag was set
in the CreateFile calls for both the input and output
files, and the input buffer was 8K long (the output buffer was 16K). Overlapped and
mutlithreaded implementations did not improve performance; in fact, they degraded
performance in many cases.
Appendix C also showed that mapping the input and output files could produce superior
performance (about three to one), at least when using NT Version 4.0 and the NTFS.
Readers have since asked several questions related to these results.
- What would happen if you processed files much larger than the 5MB input files used for
the Appendix C results? In particular, would memory-mapped performance degrade as physical
memory is exhausted and portions of the mapped file are flushed to disk?
- What would happen if the output file were to be flushed to the disk before closing the
files? The existing tests can terminate with all or part of the output file in memory but
not flushed to the disk, giving comparable but optimistic results. Note: This
current behavior is normal in most programs; we generally let the operating systems flush
buffers as it sees fit. Reliability and other considerations, however, might make it
advisable to flush the data as soon as possible.
- Would it make a difference if the input and output files were not buffered (set FILE_FLAG_NO_BUFFERING at CreateFile
time)? Perhaps we would gain performance by reducing the number of memory-memory copies.
The following graphs shows the results with much larger files. This time, the tests
were run on an NT 4.0 (SP3) 256MHz Pentium Pro system with 128MB RAM and an NTFS. There
are four atou versions.
- atouLBSS is the same as in Appendix C. This can be
considered our attempt to get the maximum performance from Win32 sequential I/O.
- atouFAFL is the same "fast version" (LB and SS) with a call to FlushFileBuffers (hOut) just
before closing the handle. This version should take longer than atouLBSS
as the data must be written to the disk.
- atouMM is the memory-mapped version developed in Chapter
6 and used in Appendix C.
- atouMMFL is the same as atouMM
except that there are calls to FlushViewOfFile and FlushFileBuffers at the end.
A fifth version, atouFANB, (no file buffering) was also
tested but was found to be too slow (a factor of 4 slower than atouLBSS),
even for the small files, to warrant obtaining additional data.
The following graph shows the results for input files as large as 44.8MB (horizontal
axis). Only the elapsed "real" times are shown.
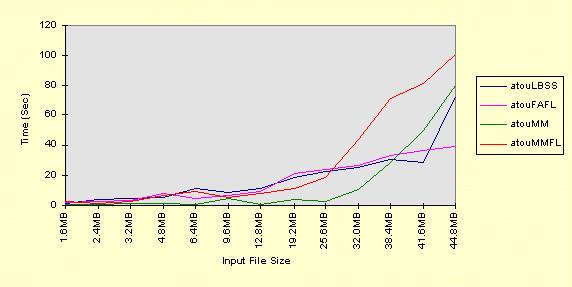
Observations:
- atouMMFL performance is consistently worse than atouMM performance, as expected (orange and green lines).
- atouLBSS (blue) and atouFAFL
(purple) are about the same, with one inexplicable anomaly for the 44.8MB file case, where
atouFAFL is significantly better. In both cases, the time
is approximately linear in the size of the input file, as expected (except for the one
anomaly).
- Memory mapping produces clearly superior results for "small" files, but
performance degrades non-linearly with larger files. Up to a certain point, the time is
approximately linear with file size, but the time becomes non-linear around 32MB. Recall
that, at this point, there will be 32MB of input file and 64MB of output file in physical
memory if there is sufficient space. It appears, however, that accesses to the mapped
input file may start to fault at this point, and the beginning of the mapped output file
must be flushed to disk. This can explain the performance degradation. Notice, also, that
the difference between the two times appears to be about constant after 32MB, perhaps due
to the fact that the amount of memory to be flushed stays constant.
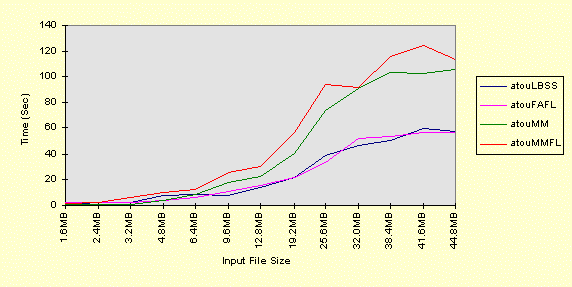
This graph is for a 100MHz Pentium with 32MB RAM running NTFS. This time, the
memory-mapped results are worse in all cases. I do not have an explanation, as these
results are at odds with all the other results that show superior performance using memory
mapping with small files.
|
 Win32 System Programming
Win32 System Programming