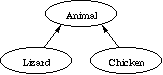
The Animal class embodies the features shared by all the creatures
you deal with, and the Lizard and Chicken classes
specialize Animal in ways appropriate for lizards and chickens,
respectively.
Here's a sketch of the definitions for these classes:
class Animal {
public:
Animal& operator=(const Animal& rhs);
...
};
class Lizard: public Animal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public Animal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
Only the assignment operators are shown here, but that's more than enough to keep
us busy for a while. Consider this code:
Lizard liz1;There are two problems here. First, the assignment operator invoked on the last line is that of the
Lizard liz2; Animal *pAnimal1 = &liz1; Animal *pAnimal2 = &liz2; ... *pAnimal1 = *pAnimal2;
Animal class, even though the objects involved
are of type Lizard. As a result, only the Animal part
of liz1 will be modified. This is a partial assignment. After
the assignment, liz1's Animal members have the values
they got from liz2, but liz1's Lizard
members remain unchanged.The second problem is that real programmers write code like this. It's not uncommon to make assignments to objects through pointers, especially for experienced C programmers who have moved to C++. That being the case, we'd like to make the assignment behave in a more reasonable fashion. As Item 32 points out, our classes should be easy to use correctly and difficult to use incorrectly, and the classes in the hierarchy above are easy to use incorrectly.
One approach to the problem is to make the assignment operators virtual. If
Animal::operator= were virtual, the assignment would invoke the
Lizard assignment operator, which is certainly the correct one to
call. However, look what happens if we declare the assignment operators
virtual:
class Animal {
public:
virtual Animal& operator=(const Animal& rhs);
...
};
class Lizard: public Animal {
public:
virtual Lizard& operator=(const Animal& rhs);
...
};
class Chicken: public Animal {
public:
virtual Chicken& operator=(const Animal& rhs);
...
};
Due to relatively recent changes to the language, we can customize the return
value of the assignment operators so that each returns a reference to the correct
class, but the rules of C++ force us to declare identical parameter types
for a virtual function in every class in which it is declared. That means the
assignment operator for the Lizard and Chicken classes
must be prepared to accept any kind of Animal object on the
right-hand side of an assignment. That, in turn, means we have to confront the
fact that code like the following is legal:
Lizard liz;
Chicken chick;
Animal *pAnimal1 = &liz;
Animal *pAnimal2 = &chick;
...
*pAnimal1 = *pAnimal2; // assign a chicken to
// a lizard!
This is a mixed-type assignment: a Lizard is on the left and a
Chicken is on the right. Mixed-type assignments aren't usually a
problem in C++, because the language's strong typing generally renders them
illegal. By making Animal's assignment operator virtual, however, we
opened the door to such mixed-type operations.This puts us in a difficult position. We'd like to allow same-type assignments through pointers, but we'd like to forbid mixed-type assignments through those same pointers. In other words, we want to allow this,
Animal *pAnimal1 = &liz1; Animal *pAnimal2 = &liz2; ... *pAnimal1 = *pAnimal2; // assign a lizard to a lizardbut we want to prohibit this:
Animal *pAnimal1 = &liz; Animal *pAnimal2 = &chick; ... *pAnimal1 = *pAnimal2; // assign a chicken to a lizardDistinctions such as these can be made only at runtime, because sometimes assigning
*pAnimal2 to *pAnimal1 is valid, sometimes
it's not. We thus enter the murky world of type-based runtime errors. In
particular, we need to signal an error inside operator= if we're
faced with a mixed-type assignment, but if the types are the same, we want to
perform the assignment in the usual fashion.
We can use a dynamic_cast (see Item 2) to implement this behavior.
Here's how to do it for Lizard's assignment operator:
Lizard& Lizard::operator=(const Animal& rhs)
{
// make sure rhs is really a lizard
const Lizard& rhs_liz = dynamic_cast<const Lizard&>(rhs);
proceed with a normal assignment of rhs_liz to *this;
}
This function assigns rhs to *this only if
rhs is really a Lizard. If it's not, the function
propagates the bad_cast exception that dynamic_cast
throws when the cast fails. (Actually, the type of the exception is
std::bad_cast, because the components of the standard library,
including the exceptions thrown by the standard components, are in the namespace
std. For an overview of the standard library, see Item 35.)
Even without worrying about exceptions, this function seems needlessly
complicated and expensive -- the dynamic_cast must consult a
type_info structure; see Item 24 -- in the common case where one
Lizard object is assigned to another:
Lizard liz1, liz2;
...
liz1 = liz2; // no need to perform a
// dynamic_cast: this
// assignment must be valid
We can handle this case without paying for the complexity or cost of a
dynamic_cast by adding to Lizard the conventional
assignment operator:
class Lizard: public Animal {
public:
virtual Lizard& operator=(const Animal& rhs);
Lizard& operator=(const Lizard& rhs); // add this
...
};
Lizard liz1, liz2;
...
liz1 = liz2; // calls operator= taking
// a const Lizard&
Animal *pAnimal1 = &liz1;
Animal *pAnimal2 = &liz2;
...
*pAnimal1 = *pAnimal2; // calls operator= taking
// a const Animal&
In fact, given this latter operator=, it's simplicity itself to
implement the former one in terms of it:
Lizard& Lizard::operator=(const Animal& rhs)
{
return operator=(dynamic_cast<const Lizard&>(rhs));
}
This function attempts to cast rhs to be a Lizard. If
the cast succeeds, the normal class assignment operator is called. Otherwise, a
bad_cast exception is thrown.
Frankly, all this business of checking types at runtime and using
dynamic_casts makes me nervous. For one thing, many compilers still
lack support for dynamic_cast, so code that uses it, though
theoretically portable, is not really portable in practice. More importantly, it
requires that clients of Lizard and Chicken be prepared
to catch bad_cast exceptions and do something sensible with them
each time they perform an assignment. In my experience, there just aren't that
many programmers who are willing to program that way. If they don't, it's not
clear we've gained a whole lot over our original situation where we were trying
to guard against partial assignments.
Given this rather unsatisfactory state of affairs regarding virtual assignment operators, it makes sense to regroup and try to find a way to prevent clients from making problematic assignments in the first place. If such assignments are rejected during compilation, we don't have to worry about them doing the wrong thing.
The easiest way to prevent such assignments is to make operator=
private in Animal. That way, lizards can be assigned to lizards and
chickens can be assigned to chickens, but partial and mixed-type assignments are
forbidden:
class Animal {
private:
Animal& operator=(const Animal& rhs); // this is now
... // private
};
class Lizard: public Animal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public Animal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
Lizard liz1, liz2;
...
liz1 = liz2; // fine
Chicken chick1, chick2;
...
chick1 = chick2; // also fine
Animal *pAnimal1 = &liz1;
Animal *pAnimal2 = &chick1;
...
*pAnimal1 = *pAnimal2; // error! attempt to call
// private Animal::operator=
Unfortunately, Animal is a concrete class, and this approach also
makes assignments between Animal objects illegal:
Animal animal1, animal2;
...
animal1 = animal2; // error! attempt to call
// private Animal::operator=
Moreover, it makes it impossible to implement the Lizard and
Chicken assignment operators correctly, because assignment operators
in derived classes are responsible for calling assignment operators in their base
classes:
Lizard& Lizard::operator=(const Lizard& rhs)
{
if (this == &rhs) return *this;
Animal::operator=(rhs); // error! attempt to call
// private function. But
// Lizard::operator= must
// call this function to
... // assign the Animal parts
} // of *this!
We can solve this latter problem by declaring Animal::operator=
protected, but the conundrum of allowing assignments between Animal
objects while preventing partial assignments of Lizard and
Chicken objects through Animal pointers remains. What's
a poor programmer to do?
The easiest thing is to eliminate the need to allow assignments between
Animal objects, and the easiest way to do that is to make
Animal an abstract class. As an abstract class, Animal
can't be instantiated, so there will be no need to allow assignments between
Animals. Of course, this leads to a new problem, because our
original design for this system presupposed that Animal objects were
necessary. There is an easy way around this difficulty. Instead of making
Animal itself abstract, we create a new class --
AbstractAnimal, say -- consisting of the common features of
Animal, Lizard, and Chicken objects, and
we make that class abstract. Then we have each of our concrete classes
inherit from AbstractAnimal. The revised hierarchy looks like
this,
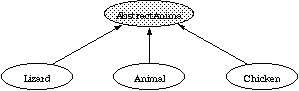
and the class definitions are as follows:
class AbstractAnimal {
protected:
AbstractAnimal& operator=(const AbstractAnimal& rhs);
virtual ~AbstractAnimal() = 0; // see below
...
};
class Animal: public AbstractAnimal {
public:
Animal& operator=(const Animal& rhs);
...
};
class Lizard: public AbstractAnimal {
public:
Lizard& operator=(const Lizard& rhs);
...
};
class Chicken: public AbstractAnimal {
public:
Chicken& operator=(const Chicken& rhs);
...
};
This design gives you everything you need. Homogeneous assignments are allowed
for lizards, chickens, and animals; partial assignments and heterogeneous
assignments are prohibited; and derived class assignment operators may call the
assignment operator in the base class. Furthermore, none of the code written in
terms of the Animal, Lizard, or Chicken
classes requires modification, because these classes continue to exist and to
behave as they did before AbstractAnimal was introduced. Sure, such
code has to be recompiled, but that's a small price to pay for the security of
knowing that assignments that compile will behave intuitively and assignments
that would behave unintuitively won't compile.
For all this to work, AbstractAnimal must be abstract -- it must
contain at least one pure virtual function. In most cases, coming up with a
suitable function is not a problem, but on rare occasions you may find yourself
facing the need to create a class like AbstractAnimal in which none
of the member functions would naturally be declared pure virtual. In such cases,
the conventional technique is to make the destructor a pure virtual function;
that's what's shown above. In order to support polymorphism through pointers
correctly, base classes need virtual destructors anyway, so the only cost
associated with making such destructors pure virtual is the inconvenience of
having to implement them outside their class definitions. (For an example, see
page 195.)
(If the notion of implementing a pure virtual function strikes you as odd, you just haven't been getting out enough. Declaring a function pure virtual doesn't mean it has no implementation, it means
=0").
You may have noticed that this discussion of assignment through base class
pointers is based on the assumption that concrete base classes like
Animal contain data members. If there are no data members, you might
point out, there is no problem, and it would be safe to have a concrete class
inherit from a second, dataless, concrete class.
One of two situations applies to your data-free would-be concrete base class: either it might have data members in the future or it might not. If it might have data members in the future, all you're doing is postponing the problem until the data members are added, in which case you're merely trading short-term convenience for long-term grief (see also Item 32). Alternatively, if the base class should truly never have any data members, that sounds very much like it should be an abstract class in the first place. What use is a concrete base class without data?
Replacement of a concrete base class like Animal with an abstract
base class like AbstractAnimal yields benefits far beyond simply
making the behavior of operator= easier to understand. It also
reduces the chances that you'll try to treat arrays polymorphically, the
unpleasant consequences of which are examined in Item 3. The most significant
benefit of the technique, however, occurs at the design level, because replacing
concrete base classes with abstract base classes forces you to explicitly
recognize the existence of useful abstractions. That is, it makes you create new
abstract classes for useful concepts, even if you aren't aware of the fact that
the useful concepts exist.
If you have two concrete classes C1 and C2 and you'd like C2 to publicly inherit from C1, you should transform that two-class hierarchy into a three-class hierarchy by creating a new abstract class A and having both C1 and C2 publicly inherit from it:
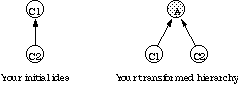
The primary value of this transformation is that it forces you to identify the abstract class A. Clearly, C1 and C2 have something in common; that's why they're related by public inheritance. With this transformation, you must identify what that something is. Furthermore, you must formalize the something as a class in C++, at which point it becomes more than just a vague something, it achieves the status of a formal abstraction, one with well-defined member functions and well-defined semantics.
All of which leads to some worrisome thinking. After all, every class represents some kind of abstraction, so shouldn't we create two classes for every concept in our hierarchy, one being abstract (to embody the abstract part of the abstraction) and one being concrete (to embody the object-generation part of the abstraction)? No. If you do, you'll end up with a hierarchy with too many classes. Such a hierarchy is difficult to understand, hard to maintain, and expensive to compile. That is not the goal of object-oriented design.
The goal is to identify useful abstractions and to force them -- and only them -- into existence as abstract classes. But how do you identify useful abstractions? Who knows what abstractions might prove useful in the future? Who can predict who's going to want to inherit from what?
Well, I don't know how to predict the future uses of an inheritance hierarchy, but I do know one thing: the need for an abstraction in one context may be coincidental, but the need for an abstraction in more than one context is usually meaningful. Useful abstractions, then, are those that are needed in more than one context. That is, they correspond to classes that are useful in their own right (i.e., it is useful to have objects of that type) and that are also useful for purposes of one or more derived classes.
This is precisely why the transformation from concrete base class to abstract base class is useful: it forces the introduction of a new abstract class only when an existing concrete class is about to be used as a base class, i.e., when the class is about to be (re)used in a new context. Such abstractions are useful, because they have, through demonstrated need, shown themselves to be so.
The first time a concept is needed, we can't justify the creation of both an abstract class (for the concept) and a concrete class (for the objects corresponding to that concept), but the second time that concept is needed, we can justify the creation of both the abstract and the concrete classes. The transformation I've described simply mechanizes this process, and in so doing it forces designers and programmers to represent explicitly those abstractions that are useful, even if the designers and programmers are not consciously aware of the useful concepts. It also happens to make it a lot easier to bring sanity to the behavior of assignment operators.
Let's consider a brief example. Suppose you're working on an application that deals with moving information between computers on a network by breaking it into packets and transmitting them according to some protocol. All we'll consider here is the class or classes for representing packets. We'll assume such classes make sense for this application.
Suppose you deal with only a single kind of transfer protocol and only a single kind of packet. Perhaps you've heard that other protocols and packet types exist, but you've never supported them, nor do you have any plans to support them in the future. Should you make an abstract class for packets (for the concept that a packet represents) as well as a concrete class for the packets you'll actually be using? If you do, you could hope to add new packet types later without changing the base class for packets. That would save you from having to recompile packet-using applications if you add new packet types. But that design requires two classes, and right now you need only one (for the particular type of packets you use). Is it worth complicating your design now to allow for future extension that may never take place?
There is no unequivocally correct choice to be made here, but experience has shown it is nearly impossible to design good classes for concepts we do not understand well. If you create an abstract class for packets, how likely are you to get it right, especially since your experience is limited to only a single packet type? Remember that you gain the benefit of an abstract class for packets only if you can design that class so that future classes can inherit from it without its being changed in any way. (If it needs to be changed, you have to recompile all packet clients, and you've gained nothing.)
It is unlikely you could design a satisfactory abstract packet class unless you were well versed in many different kinds of packets and in the varied contexts in which they are used. Given your limited experience in this case, my advice would be not to define an abstract class for packets, adding one later only if you find a need to inherit from the concrete packet class.
The transformation I've described here is a way to identify the need for abstract classes, not the way. There are many other ways to identify good candidates for abstract classes; books on object-oriented analysis are filled with them. It's not the case that the only time you should introduce abstract classes is when you find yourself wanting to have a concrete class inherit from another concrete class. However, the desire to relate two concrete classes by public inheritance is usually indicative of a need for a new abstract class.
As is often the case in such matters, brash reality sometimes intrudes on the peaceful ruminations of theory. Third-party C++ class libraries are proliferating with gusto, and what are you to do if you find yourself wanting to create a concrete class that inherits from a concrete class in a library to which you have only read access?
You can't modify the library to insert a new abstract class, so your choices are both limited and unappealing:
class Window { // this is the library class
public:
virtual void resize(int newWidth, int newHeight);
virtual void repaint() const;
int width() const;
int height() const;
};
class SpecialWindow { // this is the class you
public: // wanted to have inherit
... // from Window
// pass-through implementations of nonvirtual functions
int width() const { return w.width(); }
int height() const { return w.height(); }
// new implementations of "inherited" virtual functions
virtual void resize(int newWidth, int newHeight);
virtual void repaint() const;
private:
Window w;
};
This strategy requires that you be prepared to update your class each time the
library vendor updates the class on which you're dependent. It also requires that
you be willing to forego the ability to redefine virtual functions declared in
the library class, because you can't redefine virtual functions unless you
inherit them.
Still, the general rule remains: non-leaf classes should be abstract. You may need to bend the rule when working with outside libraries, but in code over which you have control, adherence to it will yield dividends in the form of increased reliability, robustness, comprehensibility, and extensibility throughout your software.